7 x 24 在线支持!
Oracle数据恢复专题
备份恢复是Oracle中永恒的话题, 只要有数据 就有备份恢复的需求。 而在国内对于备份以及备份的可用性往往被企业所忽视。这造成了再数据库恢复上存在着东西方的差异。 更多的老外DBA把经历花在对Oracle内部原理和性能优化的研究上。
如果不能自行解决该问题,那么也可以联系ASKMACLEAN专业数据库修复团队。
而我们国内 DBA似乎必须要精通一门额外的技术==》 在没有任何备份的情况下 恢复Oracle数据库中数据的技术! 虽然这在大多数情况下是屠龙之技, 但很多时候却又变成了衡量一个DBA技术水准的标准了,(这样不好.. 不好)。
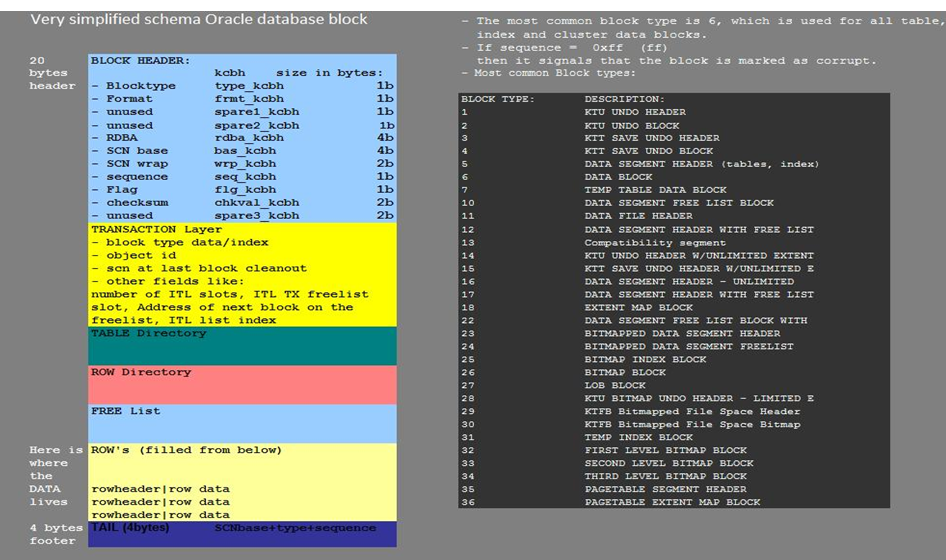
当然也并不是说 这种无备份下的数据恢复是无技术含金量的,实际上它们很需要对Oracle数据文件、数据块及其数据结构的理解,以及对数据字典构成的了解。
这里我们总结Oracle数据恢复专题的专题,包括一些在无备份情况下的数据恢复:例如DUL和BBED工具恢复等技术。
【数据恢复】利用构造ROWID实现无备份情况下绕过ORA-1578、ORA-8103、ORA-1410等逻辑/物理坏块问题
【数据恢复】ORA-600[kccpb_sanity_check_2]一例
如何清除Oracle控制文件中的无用记录,例如v$archived_log中的deleted归档日志记录
如何找回被create or replace覆盖的PL/SQL对象
Archivelog Completed Before VS UNTIL TIME
ASM丢失disk header导致ORA-15032、ORA-15040、ORA-15042 Diskgroup无法mount
Overcome ORA-600[4xxx] open database
数据恢复:解决ORA-600[kghstack_free2][kghstack_err+0068]一例
如何rename datafile name中存在乱码的数据文件
Oracle数据恢复:解决ORA-00600:[4000] ORA-00704: bootstrap process failure错误一例
Fractured block found during backing up datafile
手动递增SCN号的几种方法:How to increase System Change Number by manual
Oracle的损坏/坏块 主要分以下几种:
ORA-1578
ORA-8103
ORA-1410
ORA-1499
ORA-1578
ORA-81##
ORA-14##
ORA-26040
ORA-600 Errors
Block Corruption
Index Corruption
Row Corruption
UNDO Corruption
Control File
Consistent Read
Dictionary
File/RDBA/BL
Error Description Corruption related to: ORA-1578 ORA-1578 is reported when a block is thought to be corrupt on read. Block OERR: ORA-1578 “ORACLE data block corrupted (file # %s, block # %s)” Master Note OERR: ORA-1578 “ORACLE data block corrupted (file # %s, block # %s)” Handling Oracle Block Corruptions in Oracle7/8/8i/9i/10g/11g Diagnosing and Resolving 1578 reported on a Local Index of a Partitioned table ORA-1410 This error is raised when an operation refers to a ROWID in a table for which there is no such row.
The reference to a ROWID may be implicit from a WHERE CURRENT OF clause or directly from a WHERE ROWID=… clause.
ORA 1410 indicates the ROWID is for a BLOCK that is not part of this table.Row Understanding The ORA-1410 Summary Of Bugs Containing ORA 1410 OERR: ORA 1410 “invalid ROWID” ORA-8103 The object has been deleted by another user since the operation began.
If the error is reproducible, following may be the reasons:-
a.) The header block has an invalid block type.
b.) The data_object_id (seg/obj) stored in the block is different than the data_object_id stored in the segment header. See dba_objects.data_object_id and compare it to the decimal value stored in the block (field seg/obj).Block ORA-8103 Troubleshooting, Diagnostic and Solution OERR: ORA-8103 “object no longer exists” / Troubleshooting, Diagnostic and Solution ORA-8102 An ORA-08102 indicates that there is a mismatch between the key(s) stored in the index and the values stored in the table. What typically happens is the index is built and at some future time, some type of corruption occurs, either in the table or index, to cause the mismatch. Index OERR ORA-8102 “index key not found, obj# %s, file %s, block %s (%s) ORA-1499 An error occurred when validating an index or a table using the ANALYZE command.
One or more entries does not point to the appropriate cross-reference.Index ORA-1499. Table/Index row count mismatch OERR: ORA-1499 table/Index Cross Reference Failure – see trace file ORA-1498 Generally this is a result of an ANALYZE … VALIDATE … command.
This error generally manifests itself when there is inconsistency in the data/Index block. Some of the block check errors that may be found:-
a.) Row locked by a non-existent transaction
b.) The amount of space used is not equal to block size
c.) Transaction header lock count mismatch.
While support are processing the tracefile it may be worth the re-running the ANALYZE after restarting the database to help show if the corruption is consistent or if it ‘moves’.
Send the tracefile to support for analysis.
If the ANALYZE was against an index you should check the whole object. Eg: Find the tablename and execute:
ANALYZE TABLE xxx VALIDATE STRUCTURE CASCADE;Block OERR: ORA 1498 “block check failure – see trace file” ORA-26040 Trying to access data in block that was loaded without redo generation using the NOLOGGING/UNRECOVERABLE option.
This Error raises always together with ORA-1578Block OERR ORA-26040 Data block was loaded using the NOLOGGING option ORA-1578 / ORA-26040 Corrupt blocks by NOLOGGING – Error explanation and solution ORA-1578 ORA-26040 in a LOB segment – Script to solve the errors ORA-1578 ORA-26040 in 11g for DIRECT PATH with NOARCHIVELOG even if LOGGING is enabled ORA-1578 ORA-26040 On Awr Table Errors ORA-01578, ORA-26040 On Standby Database Workflow Tables ORA-01578 ORACLE data block corrupted ORA-26040 Data block was loaded using the NOLOGGING option ORA-1578, ORA-26040 Data block was loaded using the NOLOGGING option ORA-600[12700] Oracle is trying to access a row using its ROWID, which has been obtained from an index.
A mismatch was found between the index rowid and the data block it is pointing to. The rowid points to a non-existent row in the data block. The corruption can be in data and/or index blocks.
ORA-600 [12700] can also be reported due to a consistent read (CR) problem.Consistent Read Resolving an ORA-600 [12700] error in Oracle 8 and above. ORA-600 [12700] “Index entry Points to Missing ROWID” ORA-600[3020] This is called a ‘STUCK RECOVERY’.
There is an inconsistency between the information stored in the redo and the information stored in a database block being recovered.Redo ORA-600 [3020] “Stuck Recovery” Information Required for Root Cause Analysis of ORA-600 [3020] (stuck recovery) ORA-600[4194] A mismatch has been detected between Redo records and rollback (Undo) records.
We are validating the Undo record number relating to the change being applied against the maximum undo record number recorded in the undo block.
This error is reported when the validation fails.Undo ORA-600 [4194] “Undo Record Number Mismatch While Adding Undo Record” Basic Steps to be Followed While Solving ORA-00600 [4194]/[4193] Errors Without Using Unsupported parameter ORA-600[4193] A mismatch has been detected between Redo records and Rollback (Undo) records.
We are validating the Undo block sequence number in the undo block against the Redo block sequence number relating to the change being applied.
This error is reported when this validation fails.Undo ORA-600 [4193] “seq# mismatch while adding undo record” Basic Steps to be Followed While Solving ORA-00600 [4194]/[4193] Errors Without Using Unsupported parameter Ora-600 [4193] When Opening Or Shutting Down A Database ORA-600 [4193] When Trying To Open The Database ORA-600[4137] While backing out an undo record (i.e. at the time of rollback) we found a transaction id mis-match indicating either a corruption in the rollback segment or corruption in an object which the rollback segment is trying to apply undo records on.
This would indicate a corrupted rollback segment.Undo/Redo ORA-600 [4137] “XID in Undo and Redo Does Not Match” ORA-600[6101] Not enough free space was found when inserting a row into an index leaf block during the application of undo. Index ORA-600 [6101] “insert into leaf block (undo)” ORA-600[2103] Oracle is attempting to read or update a generic entry in the control file.
If the entry number is invalid, ORA-600 [2130] is logged.Control File ORA-600 [2130] “Attempt to access non-existant controlfile entry” ORA-600[4512] Oracle is checking the status of transaction locks within a block.
If the lock number is greater than the number of lock entries, ORA-600 [4512] is reported followed by a stack trace, process state and block dump.
This error possibly indicates a block corruption.Block ORA-600 [4512] “Lock count mismatch” ORA-600[2662] A data block SCN is ahead of the current SCN.
The ORA-600 [2662] occurs when an SCN is compared to the dependent SCN stored in a UGA variable.
If the SCN is less than the dependent SCN then we signal the ORA-600 [2662] internal error.Block ORA-600 [2662] “Block SCN is ahead of Current SCN” ORA 600 [2662] DURING STARTUP ORA-600[4097] We are accessing a rollback segment header to see if a transaction has been committed.
However, the xid given is in the future of the transaction table.
This could be due to a rollback segment corruption issue OR you might be hitting the following known problem.Undo ORA-600 [4097] “Corruption” ORA-600[4000] It means that Oracle has tried to find an undo segment number in the dictionary cache and failed. Undo ORA-600 [4000] “trying to get dba of undo segment header block from usn” ORA-600[6006] Oracle is undoing an index leaf key operation. If the key is not found, ORA-00600 [6006] is logged.
ORA-600[6006] is usually caused by a media corruption problem related to either a lost write to disk or a corruption on disk.Index ORA-600 [6006] ORA-600[4552] This assertion is raised because we are trying to unlock the rows in a block, but receive an incorrect block type.
The second argument is the block type received.Block ORA-600 [4555] ORA-600[6856] Oracle is checking that the row slot we are about to free is not already on the free list.
This internal error is raised when this check fails.Row ORA-600 [6856] “Corrupt Block When Freeing a Row Slot ORA-600[13011] During a delete operation we are deleting from a view via an instead-of trigger or an Index organized table and have exceeded a 5000 pass count when we raise this exception. Row ORA-600 [13011] “Problem occurred when trying to delete a row” ORA-600[13013] During the execution of an UPDATE statement, after several attempts (Arg [a] passcount) we are unable to get a stable set of rows that conform to the WHERE clause. Row ORA-600 [13013] “Unable to get a Stable set of Records” How to resolve ORA-00600 [13013], [5001] ORA-600[13030] ORA-600 [13030] ORA-600[25012] We are trying to generate the absolute file number given a tablespace number and relative file number and cannot find a matching file number or the file number is zero. afn/rdba/tsn ORA-600 [25012] “Relative to Absolute File Number Conversion Error” ORA-600[25026] Looking up/checking a tablespace
invalid tablespace ID and/or rdba foundafn/rdba/tsn ORA-600 [25026] ORA-600[25027] Invalid tsn and/or rfn found afn/rdba/tsn ORA-600 [25027] ORA-600[kcbz_check_objd_typ] An object block buffer in memory is checked and is found to have the wrong object id. This is most likely due to corruption. Buffer Cache ORA-600 [kcbz_check_objd_typ_3] ORA-600 [kcbz_check_objd_typ] ORA-600[kddummy_blkchk] ORA-600[kdblkcheckerror] ORA-600[kddummy_blkchk] is for 10.1/10.2 and ORA-600[kdblkcheckerror] for 11 onwards. Block ORA-600 [kddummy_blkchk] How to Resolve ORA-00600[kddummy_blkchk] ORA-600 [kdblkcheckerror]
QREF – kddummy_blkchk / kdBlkCheckError – Check Codes Listing (Full) [This section is not visible to customers.]
QREF – kddummy_blkchk / kdBlkCheckError – Check Codes Definition && Return Values[This section is not visible to customers.] ORA-600[ktadrprc-1] Dictionary ORA-600 [ktadrprc-1] ORA-600[ktsircinfo_num1] This exception occurs when there are problems obtaining the row cache information correctly from sys.seg$. In most cases there is no information in sys.seg$. Dictionary ORA-600 [ktsircinfo_num1] ORA-600[qertbfetchbyrowid] Row ORA-600 [qertbfetchbyrowid] ORA-600[ktbdchk1-bad dscn] This exception is raised when we are performing a sanity check on the dependent SCN and fail.
The dependent scn is greater than the current scn.Dictionary ORA-600 [ktbdchk1: bad dscn]
对于任何数据层面的BUG,我们在诊断时值得自问的是:
- 是否收集了基本的数据
- 这些数据损坏/坏块仅仅是发生在磁盘上的吗
- 是否实例崩溃了且起不来了?
- stack trace里是否有KDBLKCHECKERROR的信息?
- stack trace里是否有kdsgrp1的信息?
- 是否导致查询到错误的结果?
- 有哪些RDBMS特性正在被使用?
- 是否运行在Exadata上?
基础数据的收集
除非数据库已经崩溃而没法升级,否则我们总是推荐先收集基础数据,这帮助我们了解数据库的运行历史情况。 一个重要的信息在于要找出哪些问题对象的DDL语句,这让我们知道它使用了哪些RDBMS特性,例如表上有 LOB大对象 的情况和没有的情况就完全不一样。
数据结构
首先搞清楚哪些对象涉及到这个问题中
- 搞清楚以来的对象 例如索引,约束等等
- 这个问题是发生在普通堆表上吗? 是什么类型的堆表? 无压缩,OLTP压缩还是 EHCC压缩?
- 问题和 LOB有关吗? 是Securefile还是BasicFile? 高级Securefile特性还包括压缩 加密等
- 问题发生在 IOT上吗?
- 问题发生在索引上吗? 无压缩,压缩还是bitmap index?
- 表的基础上是否定义了视图?
- 表或索引是否分区了? 如果是,何种分区? 多少分区?
- 如果表被分区了,是本地还是全局索引?
ALERT和TRACE文件
alert.log和trace文件对于此类意外是必要查看的。一般只收集相关文件,因为其内容已经足够丰富了,一般不收集整个udump和 bdump目录。 alert.log 最好能完整一些,要包含第一次发生该错误,同时这也让我们能够参考发生问题的init.ora参数文件信息。 如果是一系列相同的错误,那么提供前几个trace文件较好,而不是后来生成的。
对于 RAC而言要查看所有节点上的alert.log
Redo重做
请收集如下关于 redo的 dump:
- 获得对应的redo block dump, BLOCK号可以从错误trace中获得
- 从之前的归档中转储redo dump
- 如果之前的备份可用,那么把原始的数据块从备份中搞一份出来
磁盘上的损坏/坏块
磁盘上的数据块损坏/坏块是较为严重的问题 可能导致数据丢失。所以确认到底是不是发生在磁盘上的corruption很重要。 如果我们怀疑一张表上存在磁盘上的损坏,那么做下面的事情:
-
运行DBV:
- DBV可以指定运行在某个数据文件或者一整个块上, 前提是你知道 块号, 那么先针对块运行
- 如果你确认不到块,那么对整个数据文件运行
-
运行 SELECT * FROM TABLE;
- SELECT * FROM TABLE,运行该语句对于确认表上的数据是否还能被全部读出做判断, 可以配合 alter system flush buffer_cache运行
- 如果运行SELECT * FROM TABLE 的输出太多了,那么可以运行例如’select max(col1), max(col2) … max(colN) from Table’; 或者自己写一个游标循环
- 运行ANALYZE TABLE VALIDATE STRUCTURE
通过上面的分析, 我们可以确认下面的问题了:
-
检查block cache header是否正常
- 检查 dba、scn、checksum、 tail和format
- 如果cache header不正常,那么是数据层面的问题的概率不大
- 检查缓存或者VOS层
- 有多少块损坏了呢? 如果有非常多, 则不太可能是oracle bug导致的
- 有多少表或分区损坏了呢? 收集那些对象涉及到此问题的,以及其DDL等基础信息
- 有多少行数据被影响了?
为了实现root cause analysis根本原因的分析, 以下的信息总是需要的:
- 所有RAC节点的alert.log
- 此意外事件相关的所有trace文件
- 该坏块相关的完整的redo logfile, 它们也可能来自于归档文件
- 如果有可用的备份,从备份中取出一份原始数据块
同时我们有必要向用户推荐
- 设置db_block_checking=true
- 指定今后的恢复策略
Assistant: Get Assistance to understand and solve Oracle Database Server Corruptions (Doc ID 1543698.2)
需要注意的是 不仅仅ORACLE BUG可能造成这些损坏/坏块, 引起这些corruption问题的另一个主要原因是 OS操作系统、 卷管理器volume manager 或者存储引起的, 因为ORACLE仅仅是一个程序 作为这些底层建筑的使用者。
已知的一些由于 硬件/OS/卷管理引起的corruption如下:
cause:
This type of timestamps is used by Veritas Netbackup tool. Netbackup is corrupting the block in a backup.
Netbackup is a 3rd party tool provided by Symantec/Veritas and it can be used with RMAN.
Netbackup should be reading from Oracle files, but somehow it is writing timestamps into the Oracle file head
To prevent this corruption: this issue is known by Symantec/Veritas, and it is fixed beginning with Netbackup client 5.1 MP6 or 4.5 MP9. Open a case with Symantec/Veritas if more information is needed.
该问题的原因是Netbackup NBU早期版本可能直接写时间戳到ORACLE 文件头
Physical Corrupted Blocks consisting of all Zeroes indicate a problem with OS, HW or Storage (Doc ID 1545366.1)
这个Note 介绍 有一些OS或硬件问题 导致数据块变全零, 但ORACLE的设计并不会写出全零到数据块
Oracle by design does not write blocks of all zeroes.
This is done to easily identify problems in the underlying operating system, hardware or storage. This is enforced by Oracle checks that are enabled by default before writing any data or redo block. No special parameters are needed to enable these checks nor can anyone disable them. Every Oracle process that writes changes to the disk abides by these rules. Oracle has seen bugs in hardware, operating system, firmware and storage that result in zero out blocks. Oracle deliberately avoids writing complete zero blocks so it easily detects when external forces caused these data block corruptions. Every Oracle data block, controlfile, redo and tempblocks are stamped with minimally set of meta data. For data blocks, each block is formatted to include the block offset address (rdba), block format, a flag, tail and checksum within the datafile. When a new datafile is created, Oracle stamps every block with these fields. Redo logs are similarly pre-formatted or initialized before being used in the database.
Ensuring Oracle never writes zeroed out blocks is also checked at the lowest levels of the database, right before Oracle issues the write() call to the Operating System. If the Oracle RDBMS detects an all-zero block at the point of the write is issued to the operating system, an error ORA-600 is produced or the block is reported as corrupt in the alert log; the block then is not written to disk.
Storage vendors have implemented checks based on the Oracle design of not writing zeros.
This Oracle property (not writing zero blocks) is now checked by some storage vendors to avoid some of these corruptions caused by operating system or storage.
EMC Double Checksum checks for a non-zero DBA field in Oracle blocks. An all-zero block by definition fails checks. Hitachi Database Validator performs the same check. Oracle Exadata performs these, and additional, more comprehensive (HARD) checks.
If Oracle wrote all-zero blocks, it would never have allowed these checks to be implemented into third-party hardware.
ORA-354 Redo log corruption when using Xisgo Driver (Doc ID 1498389.1)
Xisgo Driver 可能引起 redo logfile 损坏
Database Corruption due to Lost IO on Hitachi storage. ORA-600 [kdsgrp1] ORA-1499 ORA-1410 ORA-600 [3020] (Doc ID 1512717.1)
Hitachi Storage 日立存储的微码可能导致 LOST Write写丢失问题,导致镜像不同步, 进而ORACLE出现大量如下错误
Wrong results
ORA-600 [kdsgrp1]
ORA-600 [qertbFetchByRowID]
ORA-1499 by analyze validate structure cascade
ORA-8102
ORA-600 [25027]
ORA-600 [kcbz_check_objd_typ_3]
ORA-8103
ORA-1410
ORA-600 [kclchkblk_3]
ORA-600 [4137]
ORA-600 [4193]
ORA-600 [4194]
During Media Recovery:
ORA-600 [3020]
ORA-00752 (when DB_LOST_WRITE_PROTECT is enabled – 11g)
Workaround
In order to workaround the problem please first contact Hitachi to repair storage mirror inconsistency; in addition, evaluate and implement one of the following Oracle workarounds:
If using a Dataguard environment with a Physical Standby Database consider to switchover to the standby. The physical standby database may detect this problem with an ORA 600[3020] or ORA-752, then the database can be failed over to the standby database with data loss but with a database free of inconsistencies. The error provides an early detection mechanism and prevents further logical block corruptions. If the standby is using Hitachi Storage that is exposed to this problem, then the standby itself could be logically corrupted too.
Determine when problem started and restore the database from a point in time before it happened.
Recreate the affected objects but be aware that there is no deterministic means to find out the extent of the logical corruption in the database. Use all the checks in Note 836658.1 to try to identify inconsistencies.
Restore the database and apply media recovery. This may fail with ORA-600 [3020] or ORA-752 and decide to stop when these errors are encountered.
Fix/Solution
To prevent this problem from happening contact Hitachi for a fix.
ORA-1578 Transient Corruption – Caused by Parity Error on EMC DMX4 (Doc ID 1486903.1)
EMC DMX4阵列存储可能导致临时性的ORA-1578错误
DBV would often not detect any corruption, when it did it often showed 8 consecutive blocks. Usually the blocks reported were found in dba_free_space with basically the same string written across the block. Frequently 8 consecutive 32K blocks were corrupted which seemed to match up to a write for a 256K allocation unit. DBVERIFY - Verification starting : FILE = /padb/index/o1_mf_partner__5svmocgf_.dbf Page 305361 is marked corrupt *** Corrupt block relative dba: 0x1684a8d1 (file 90, block 305361) Bad header found during dbv: Data in bad block - type: 5 format: 0 rdba: 0x0fc27bbc last change scn: 0x58fe.03282668 seq: 0xe4 flg: 0x9e consistency value in tail: 0xcd163ffa check value in block header: 0xf3b4, computed block checksum: 0x0 spare1: 0xdc, spare2: 0x56, spare3: 0x190 *** Page 305362 is marked corrupt *** Corrupt block relative dba: 0x1684a8d2 (file 90, block 305362) Bad header found during dbv: Data in bad block - type: 5 format: 0 rdba: 0x0fc27bbf last change scn: 0x58fe.03282668 seq: 0xe4 flg: 0x9e consistency value in tail: 0xcd163ffa check value in block header: 0xc743, computed block checksum: 0x0 spare1: 0xdc, spare2: 0x56, spare3: 0x190 *** The application also would fail (indicating data and index blocks were also affected) Corrupt block relative dba: 0x1384a736 (file 78, block 304950) Bad header found during buffer read Data in bad block - type: 5 format: 0 rdba: 0x0ac2745b last change scn: 0x58ec.be15e45c seq: 0xe4 flg: 0x9e consistency value in tail: 0x0f223ffa check value in block header: 0x58df, computed block checksum: 0x0 spare1: 0xdc, spare2: 0x56, spare3: 0x190 *** Reread of rdba: 0x1384a736 (file 78, block 304950) found same corrupted data However, subsequent runs of the application process would find valid data (reflecting the transient nature of the corruption). Also at the exact minute ( in ten minutes intervals 4, 14, 24, 34, 44, 54 on the hour) when the corruption was reported, it was nearly always detected on more than one server. It was the same type of corruption just different blocks. Cause EMC Parity Issue. The corruption was detected at various times by the application (ORA-1578), RMAN and by DBV running against the datafile. The source of the corruption could not be determined until it was called in Virtual Instruments to detect what was occurring on the fabric. The corruption reported by Oracle was related to the parity (cache) on the EMC DMX4 array. There is a parity check run against the disk. If the disk is busy the device will build an image from parity and provision it. There was something wrong with the parity check causing it to provide invalid data. First read against the parity generated image failed, the second against the disk was successful. EMC Engineering found that corruption is evident from the DMX4 to the host – but not when reading from the primary data disk, but when they try to satisfy a read request by using parity to figure out the data needed (this is done only when the production data disk is busier and the parity short cut should in theory take less time). The problem is that Parity on some devices seems to be corrupt (although it was not detected until engineering went in and scanned at the byte level) so we end up sending back bad data, although the Sym thinks it’s good. EMC is doing a root cause analysis. They think that a rebalance failed during a disk replacement introducing the corruption. Because no disk errors were being reported internal checks on the DMX4 were not triggered. Solution EMC fixed the parity on the devices by rebuilding all the devices.
ORA-1578 ORA-353 ORA-19599 Corrupt blocks with zeros when filesystemio_options=SETALL on ext4 file system using Linux (Doc ID 1487957.1)
filesystemio_options=SETALL + EXT4 文件系统可能导致 ORA-1578 ORA-353 ORA-19599等坏块,这是kernel-uek-2.6.39-200.29.3.el6uek内核的BUG
Database files on ext4 File System on Linux and Database parameter filesystemio_options is set to SETALL.
Cause
Database files on ext4 File System on Linux and Database parameter filesystemio_options is set to SETALL.
This is a Linux defect when using O_SYNC|O_DIRECT on ext4 file systems (filesystemio_options=SETALL open the database files using O_SYNC|O_DIRECT).
Solution
This is a Linux defect known to be fixed in OS Linux version kernel-uek-2.6.39-200.29.3.el6uek.
Workaround:
The workaround to avoid corruptions in the Oracle database files is to set filesystemio_options=NONE or
filesystemio_options=DIRECTIO or filesystemio_options=ASYNCH in the database parameter file (spfile / init.ora).
To repair the affected blocks:
Use RMAN Blockrecover or Datafile media recovery. Reference Note 1578.1
ORA-1578 Misplaced blocks against datafiles stored in NFS filers (Doc ID 1525108.1)
由于使用相同的 IP 可能导致NFS 或者NAS导致ORA-1578 坏块, ORACLE作为用户程序 无法了解到这些底层的问题
It was identified that there were two devices using the same IP address. There were network packets going to switch-server-switch causing low performance with high cpu usage. That network was in the same network used by the NAS storage. It looks like that when the affected switch came online it corresponded near to when the corruption was reported. This is not an Oracle defect. Solution Workaround: If the blocks are already corrupt, use RMAN block media recovery or Datafile media recovery to repair the corruption (rfile#=45 in our example above). Solution: There are not new corruptions after the duplicate IP was fixed. P lease contact the SYSADMIN or NFS filer admin for any further information as fixing IP addresses is not part of Oracle Software.
ORA-1578 ORA-354 ORA-600 [3020] Misplaced blocks by Symantec / Veritas after adding LUN (Doc ID 1323532.1)
Veritas /Symantec 的卷管理器 当使用 PERSISTENCE=NO 时存在BUG ,导致 IO丢失:
Changes
A new LUN has been added with PERSISTENCE set to NO while the Oracle database is OPEN.
Cause
The cause of the issue is a bug on the Veritas layer when presenting LUNs (new or existing ones) with PERSISTENCE=NO.
It is supposed to make sure all I/O is halted before rearranging the existing LUN names to accommodate the new LUN
(when Veritas PERSISTENCE parameter is set to NO it means the disk names can float when new LUNs are added and upon server reboot).
The Veritas VXIO bug causes the IOs to be miss-directed for a few seconds.
Solution
Workaround:
Set PERSISTENCE to YES before adding LUN. Contact Symantec / Veritas for more information.
If the blocks are already corrupt, use RMAN block media recovery or Datafile media recovery to repair the corruption (rfile#=5 in our example above).
As this could also cause a missing write in the original block were the IO was intended to go to in the first place (rfile#=10 in our example above),
the recovery of this block may produce ORA-600 [3020] for which a Point In Time Recovery before problem happens can be the best overall solution to get a consistent database.
Solution:
To prevent this issue from happening contact Symantec about:
Symantec Technote Tech158119
Symantec etrack product defect incident 2349352
Symantec Issue will be resolved in 5.0MP3RP5P1
The fix is platform dependent. For more information reference technote TECH158119:
http://www.symantec.com/business/support/index?page=content&id=TECH158119
ORA-1578 blocks overwritten by EMC Networker – RMAN Networker Module for Oracle (NMO) (Doc ID 1323567.1)
EMC Networker Module for Oracle (NMO)的 BUG可能导致数据块被EMC覆盖掉
Changes EMC Networker Module for Oracle (NMO) has been installed. Cause This is caused by EMC Bug LGTSC23600 Issue with nmo 4.5 scheduling an RMAN backup. Solution Workarounds To prevent the issue from happening downgrade from nmo 4.5 to nmo 4.2. To repair the corruption use RMAN block media recovery or Datafile Media Recovery. Solution Contact EMC to install a fix for EMC Bug LGTSC23600.
ORA-1578 Block overwritten with string “DiskDescription cyl alt hd sec” when using Symantec / Veritas (Doc ID 1313454.1)
Symantec / Veritas的metadata存在限制,可能导致 ORACLE数据块被误覆盖
Disks have been installed using Symantec / Veritas
Cause
Symantec has confirmed it as a limitation with their software :
There is limitation of the size of the metadata of the volume manager. Max size of VTOC (volume table of contens) is 65535.
If number of cylinders for a lun exceeds this limit, metadata may be written into data part of disk and thus may corrupt blocks in filesystems.
Solution
To repair the block:
Use RMAN Blockrecover or Datafile media recovery.
If the affected block is the OS BLock header, resize the datafile.
Contact Symantec for more information about this limitation.
ORA-1578 Data Block Corruptions when using EMC Storage. Blocks with 0xc9 byte (Doc ID 1323108.1)
EMC 存储的raid机制可能导致ORA-1578
Changes RAID 5 and EMC storage. Cause From EMC: EMC new disks have generic data from the factory C9C9C9 repeated pattern. When using RAID 5, if defective SAN disks are detected upon power-up, hot spare disk are kicked in automatically to replace the bad drives. The hot-spare were prematurely declared as ready, before the data completes the reconstruction. Hot-spare unfortunately claimed to be authoritative to provide data whereas it still had the generic data from the factory (ie. C9C9C9 repeated pattern) Solution Workaround Oracle database Blocks can be repaired using RMAN Block media recovery or Datafile media recovery. Solution Contact EMC to get a fix for software bug seen on code level 5773-141. EMC manually drops the hot-spare and forces it to resync, reconstructing the data. Database are requested to remain down to avoid further potential corruption.
Block Corruption (ALL ZERO) detected after reclaiming space on Veritas Filesystem (Doc ID 1587427.1)
Symptoms
RDBMS is reporting corrupted blocks with Zeroes after the underlying diskspace has been 'reclaimed'. Example from RMAN validate:
Hex dump of (file 15, block 783824) in trace file /u01/app/oracle/diag/rdbms/orcl/ORCL/trace/ORCL_ora_12515.trc
Corrupt block relative dba: 0x03cbf5d0 (file 15, block 783824)
Completely zero block found during validation
Reread of blocknum=783824, file=/u01/oradata/orcl/datafile_08.dbf. found same corrupt data
Reread of blocknum=783824, file=/u01/oradata/orcl/datafile_08.dbf. found same corrupt data
Reread of blocknum=783824, file=/u01/oradata/orcl/datafile_08.dbf. found same corrupt data
Reread of blocknum=783824, file=/u01/oradata/orcl/datafile_08.dbf. found same corrupt data
Reread of blocknum=783824, file=/u01/oradata/orcl/datafile_08.dbf. found same corrupt data
This may also produce ORA-1578 or ORA-8103 if the corrupt block is read by a SQL statement.
Cause
Corruption is caused by an issue in the Veritas Software : Thin Reclamation problem.
This is outside of the Oracle RDBMS.
Solution
Symantec provided a fix for the issue :
VxVM Hot-fix has been released and created for Solaris Sparc, 6.0.3.011 (vm-sol10_sparc-6.0.3.011).
VRTSaslapm 6.0.100.201 is required when install VxVM Hot-fix 6.0.3.011.
Symantex recommends all customers to install this fix when using thin reclamation with VxVM and DMP.
Contact Symantec if more information is needed.
Symantec Article: TECH209201 :
Veritas Volume Manager (VxVM) 6.0.3 (Solaris Sparc) VxVM thin reclamation functionality can cause disk label loss or private/public region corruption issue.Copyright © 2013, 2019, parnassusdata.com. 版权所有。 dbrecover.com
 沪公网安备 31010802001377号
沪公网安备 31010802001377号