7 x 24 在线支持!
ORACLE専用データ復旧ソフトウェアPRM-DULユーザーズ・マニュアル
Download PRM-DUL:
http://parnassusdata.com/sites/default/files/ParnassusData_PRMForOracle_3206.zip
概述 サマリー
ParnassusData Recovery Manager(以下略してPRM)は企業レベルのOracleデータディザスタリカバリーソフトで、OracleデータベースのインスタンスでSQLを 実行することじゃなく、直接にOracle9i,10g,11g,12cからデータベースのデータフィイルを抽出することにより、目標データを救うソフト である。ParnassusData Recovery ManagerはJavaに基づいて開発された安全性が高く、ダウンロードして解凍したあと、インストールすることなしにそのままで運用できて、とっても 便利で使いやすいなソフトである。
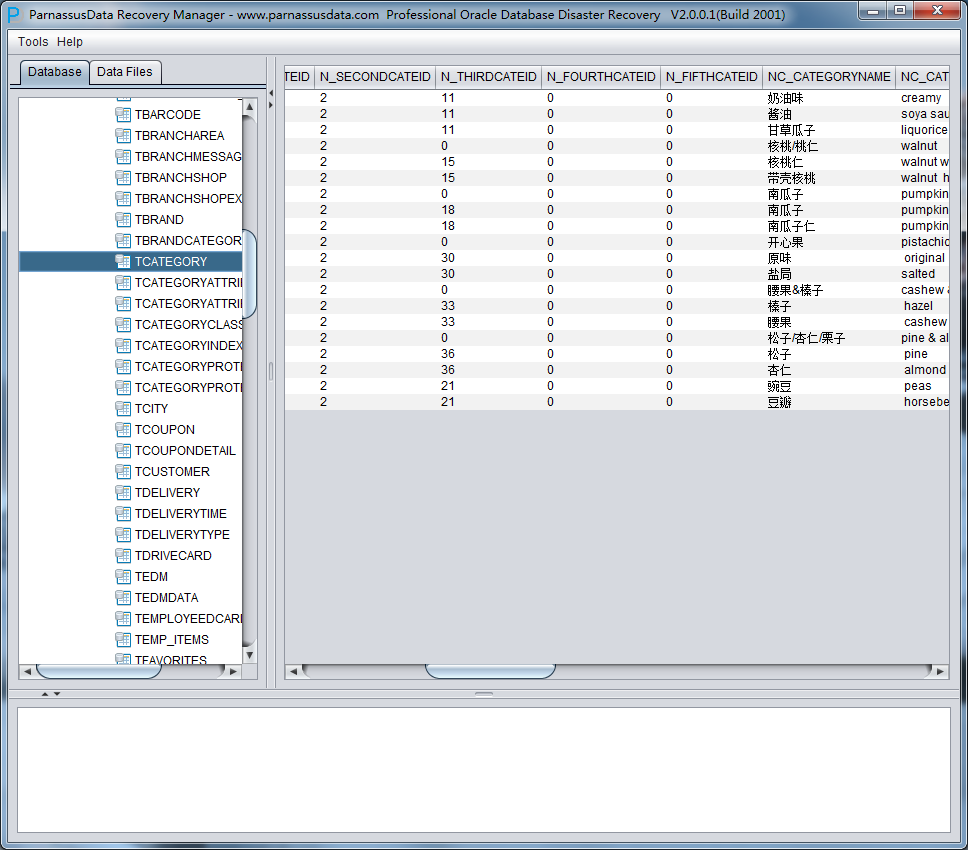
PRMはGUIグラフィカルインターフェース(図1)を採用し、新たなプログラミング言語をあらかじめ勉強する必要はなく、Oracle bottom-level structure of database原理さえわかっていれば、リカバリーウィザード(Recovery Wizard)を使うことによって、データをリカバリーできる。
なぜPRMを使う必要があるでしょう?
お客様きっとまだこういう疑問を抱いているでしょう:「RMANという応用歴史が長いOracleリカバリーマネジャーのバックアップによるリカバリーはまだ足りないというのか。なぜわざわざPRMを買う必要があるでしょう。」
ご存知の通りですが、今企業に発展し続けていくITシステムでは、データボリュムがまさに日進月歩である。データの整合性を確保することは何より大 事ですが、このデータが爆発的に増加する時代のなか、今日のOracle DBAたちは既存のディスクボリュムが不足で、データ全体を格納できないやテープによるバックアップがリカバリーするときに要する時間が予想した平均修復 時間に超えていたなどさまざまな課題に直面している。
「データベースにとって、バックアップは一番大事である」ということわざはあらゆるDBAのこころに刻んでいる。けど、現実の環境は千差万別で、筆 者の経験では、企業データベース環境でバックアップスペースが足りないとか、購入したストレージデバイスが短期的に手に入ることができないとか、バック アップしていたが、実際にリカバリーしているとき、使えなくなったとか、現場に起きることが実に予想できない。
現実によくあるリカバリートラブルに対応するため、PRM 诗檀データベースリカバリーマネジャーソフトは開発された。PRM 诗檀データベースリカバリーマネジャーソフトはORACLEデータベース内部データ構造理解したうえで、全くバックアップしていないときにSYSTEM テーブルスペースなくしたとか、ORACLEデータディクショナリーテーブルを誤操作したとか、電源がきれたことによりデータディクショナリー一貫性をな くし、データベースを起動できないとか、さまざまな難題に対応できる。さらに、誤切断(Truncate)/削除 (Delete)業務データテーブルなど、人為的な誤操作もリカバリーできる。
Oracle専門家に限っていることじゃなく、わずか数日間しかOracleデータベースを接触していなかった方にも自由自在に運用できる。このす べてはPRMのインストールがとびきりたやすいところとグラフィカル対話型インタフェースのおかげです。これにより、リカバリーを実行する技術者たちは データベースに関する専門知識を要することじゃなく、あらためて新たなプログラミング言語を勉強する必要もない。データベースの基礎になる格納構造につい てはなおさらです。マウスをクルックするだけで、余裕をもってリカバリーできる。
伝統的なリカバリーツールであるDULにたいして、PRMはDULがかなわない強みをもっている。DULはOracleオリジナル内部リカバリー ツールであて、使うたびに必ずOracle内部プロセスに通する。一般的に、Oracle現場技術サポートを購入した少しのユーザーがOracle会社か ら派遣されたエンジニアの支援の元に、リカバリー作業が始められる。PRMは少数の専門家しかデータベースリカバリー作業しか務められないという現実を一 新し、データベースがトラブルを起きる時点からリカバリー完了するまでの時間を大幅に短縮したから、企業のリカバリーコストを大分軽減した。
PRMを通ってリカバリーするには二つパータンにわけている。伝統的な抽出方法として、データをファイルから完全抽出して、フラットテキストファイ ルに書き入れて、そしてSQLLDRなどツールでデータベースへロードする。伝統の使い方がわかりやすいが、既存二倍のデータボリュームのスペースを要求 するというデメリットがある。つまり、ひとつのフラットテキストファイルが占めているスペースとあとでテキストデータをデータベースにロードするスペー ス。時間についても、元のデータをファイルから抽出したから、新規データベースにロードできるため、常に二倍の時間を必要としている。
もう一つはわたしたちPRMにより、独創的なデータバイパスモード、つまりPRMを通ってじかにデータを抽出し、新規や他の使用可能なデータベースにロードする。これより、着陸データストレージに避けて、伝統の方法に比べて、さらに時間もスペースも節約できる。
いま、Oracle ASMの自動ストレージ管理技術はより多くの企業により採用されて、このシステムは伝統のファイルシステムよりずっと多くのメ リットをもっている。例えば、性能がより高く発揮できるところ、クラスタを支持しているところ、そして管理するとき、とても便利のところ。でも、普通の ユーザーにとって、ASMの格納構造があんまりにわかりにくく、いざASMであるDisk Groupの内部データ構造が故障になって、Disk GroupがMOUNTできなくなる。つまり、ユーザーたち大事なデータをASMに閉じ込まれた。こういうときは、必ずASM内部構造に詳しい Oracle会社の専門家を現場に要請して、手動的にトラブルを解決する術しかない。でも、Oracle会社の現場技術サポートを買うには大量な資金が必 要としている。
そこで、PRMの開発者(前Oracle会社シニアエンジニア)はOracle ASM内部データ構造に対する幅広い知識に基づき、PRMでは、ASMに対するデータリカバリー機能を追加した。
今PRMが支持しているASMに対するデータリカバリー機能は以下ご覧のとおり:
1. たとえDisk Groupが正常にMOUNTできなくても、PRMを通って、ASMディスクに使用可能なメタデータを読み取ることができる、さらにこれらのメタデータがDisk GroupにあるASMファイルをコーピーすることもできる。
2. たとえDisk Groupが正常にMOUNTできなくても、PRMを通って、ASMにあるデータファイルを読み取ることやそのまま抽出することも支持する。抽出する方法については、伝統的な抽出方法とデータバイパスモード両方も支持している。
PRMソフト紹介
ParnassusData Recovery Manager(PRM)はJavaに基づいて開発されたから、PRMがいろんなプラットフォームに運用できる。AIX、Solaris、HPUXなどの Unixプラットフォームも、Redhat、Oracle Linux、SUSEやLinuxプラットフォームも、あるいはWindowsプラットフォームも直接にPRMを運用できる。
PRMが支持しているオペレーティングシステム:
| Platform Name | Supported |
| AIX POWER | ü |
| Solaris Sparc | ü |
| Solaris X86 | ü |
| Linux X86 | ü |
| Linux X86-64 | ü |
| HPUX | ü |
| MacOS | ü |
PRMが支持しているデータベースバーション
| ORACLE DATABASE VERSION | Supported | |
| Oracle 7 | û | |
| Oracle 8 | û | |
| Oracle 8i | û | |
| Oracle 9i | ü | |
| Oracle 10g | ü | |
| Oracle 11g | ü | |
| Oracle 12c | ü |
一部の古いサーバがまだAIX 4.3 Linux 3のような古いオペレーティングシステムを使っているため、このようなシステムでは最新なJDK(例えば、1.6/1.7)をインストールできないかもし れないので、PRM開発者たちはこのようなことを防ぐために、JDK1.4のプラットフォームを運用できれば、PRMを運用できるようにした。
また、Oracle10gデータベースサーバソフトはJDK1.4をもっていて、11gもJDK1.5もっているから、Oracle10g以後のどんなバーションもPRMを運用できるようになっていて、ほかのJDKをインストールする必要がない。
对于没有安装JDK 1.4版本的环境,建议从以下地址下载
JDK1.4バーションをインストールしていない環境では、いかのアドレスにダウロドしてください。
http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-arc...
PRMが使用できるもっとも古いJavaソフト環境はJDK1.4ですが、JDK1.4後が、Javaプログラムの性能が大きく上昇してきたから、PRMがJDK1.6環境でのリカバリースピードがJDK1.4より大分上回っている。
PRMを使用できる最小ハードウェア要件
| CPU中央処理装置 | せめて800 MHZ |
| 物理メモリー | せめて512 MB |
| ディスクスペース | せめて50 MB |
PRMを使うときに推薦するハードウェア構成
| CPU中央処理装置 | 2.0 GHZ |
| 物理メモリー | 2 GB |
| ディスクスペース | 2 GB |
今PRMを支持している言語
| 语言 | 字符集 | 对应的编码 |
| 中国語 簡体字/繁体字 | ZHS16GBK | GBK |
| 中国語 簡体字/繁体字 | ZHS16DBCS | CP935 |
| 中国語 簡体字/繁体字 | ZHT16BIG5 | BIG5 |
| 中国語 簡体字/繁体字 | ZHT16DBCS | CP937 |
| 中国語 簡体字/繁体字 | ZHT16HKSCS | CP950 |
| 中国語 簡体字/繁体字 | ZHS16CGB231280 | GB2312 |
| 中国語 簡体字/繁体字 | ZHS32GB18030 | GB18030 |
| 日本語 | JA16SJIS | SJIS |
| 日本語 | JA16EUC | EUC_JP |
| 日本語 | JA16DBCS | CP939 |
| 韓国語 | KO16MSWIN949 | MS649 |
| 韓国語 | KO16KSC5601 | EUC_KR |
| 韓国語 | KO16DBCS | CP933 |
| フランス語 | WE8MSWIN1252 | CP1252 |
| フランス語 | WE8ISO8859P15 | ISO8859_15 |
| フランス語 | WE8PC850 | CP850 |
| フランス語 | WE8EBCDIC1148 | CP1148 |
| フランス語 | WE8ISO8859P1 | ISO8859_1 |
| フランス語 | WE8PC863 | CP863 |
| フランス語 | WE8EBCDIC1047 | CP1047 |
| フランス語 | WE8EBCDIC1147 | CP1147 |
| ドイツ語 | WE8MSWIN1252 | CP1252 |
| ドイツ語 | WE8ISO8859P15 | ISO8859_15 |
| ドイツ語 | WE8PC850 | CP850 |
| ドイツ語 | WE8EBCDIC1141 | CP1141 |
| ドイツ語 | WE8ISO8859P1 | ISO8859_1 |
| ドイツ語 | WE8EBCDIC1148 | CP1148 |
| イタリア語 | WE8MSWIN1252 | CP1252 |
| イタリア語 | WE8ISO8859P15 | ISO8859_15 |
| イタリア語 | WE8PC850 | CP850 |
| イタリア語 | WE8EBCDIC1144 | CP1144 |
| タイ語 | TH8TISASCII | CP874 |
| タイ語 | TH8TISEBCDIC | TIS620 |
| アラビア語 | AR8MSWIN1256 | CP1256 |
| アラビア語 | AR8ISO8859P6 | ISO8859_6 |
| アラビア語 | AR8ADOS720 | CP864 |
| スペイン語 | WE8MSWIN1252 | CP1252 |
| スペイン語 | WE8ISO8859P1 | ISO8859_1 |
| スペイン語 | WE8PC850 | CP850 |
| スペイン語 | WE8EBCDIC1047 | CP1047 |
| ポルトガル語 | WE8MSWIN1252 | CP1252 |
| ポルトガル語 | WE8ISO8859P1 | ISO8859_1 |
| ポルトガル語 | WE8PC850 | CP850 |
| ポルトガル語 | WE8EBCDIC1047 | CP1047 |
| ポルトガル語 | WE8ISO8859P15 | ISO8859_15 |
| ポルトガル語 | WE8PC860 | CP860 |
PRMが支持しているテーブル格納タイプ:
| テーブル格納タイプ | 支持しているか否か |
| Cluster Tableクラスタ化表 | YES |
| 索引構成表,パーティションまたは非パーティション | YES |
| 通常のヒープテーブル、パーティションまたは非パーティション | YES |
| 一般的なヒープテーブルは、基本的な圧縮を有効にします | YES(Future) |
| 一般的なヒープテーブルは、高度な圧縮を有効にします | NO |
| 一般的なヒープテーブルは、ハイブリッド列圧縮を有効にします | NO |
| 一般的なヒープテーブル暗号化を有効にします | NO |
| 仮想列と仮想フィールドをもつテーブル | NO |
| チェーン行、行移行、chained rows 、migrated rows | YES |
注意事項:virtual column、11g optimized default columnに対して、データを抽出することは問題ないと思っているが、該当するフィールドをなくす可能性がある。これらも11gから追加した新しい機能 ですが、運用している技術者があまりいない。
PRMが支持しているデータタイプ
| データタイプ | 支持しているか否か |
| BFILE | No |
| Binary XML | No |
| BINARY_DOUBLE | Yes |
| BINARY_FLOAT | Yes |
| BLOB | Yes |
| CHAR | Yes |
| CLOB and NCLOB | Yes |
| Collections (including VARRAYS and nested tables) | No |
| Date | Yes |
| INTERVAL DAY TO SECOND | Yes |
| INTERVAL YEAR TO MONTH | Yes |
| LOBs stored as SecureFiles | Future |
| LONG | Yes |
| LONG RAW | Yes |
| Multimedia data types (including Spatial, Image, and Oracle Text) | No |
| NCHAR | Yes |
| Number | Yes |
| NVARCHAR2 | Yes |
| RAW | Yes |
| ROWID, UROWID | Yes |
| TIMESTAMP | Yes |
| TIMESTAMP WITH LOCAL TIMEZONE | Yes |
| TIMESTAMP WITH TIMEZONE | Yes |
| User-defined types | No |
| VARCHAR2 and VARCHAR | Yes |
| XMLType stored as CLOB | No |
| XMLType stored as Object Relational | No |
PRMがASMに’対する支持
| ファンクション | 支持しているか否か |
| ASMから直接にデータを抽出し、ファイルにコーピーする必要がない | YES |
| ASMからデータをコーピーする | YES |
| ASM metadataを修復する | YES |
| ASMブラックボックスをグラフィカルに示す | Future |
PRMのインストールと起動
PRMはJavaに基づくソフトですから、インストールする必要がなく、ZIPパッケージをダウロドしてから解凍したままでデータをリカバリーに運用できる。
| unzip prm_latest.zip |
诗檀はコマンドラインでPRMを起動することをすすめている。この操作によって、より多くの診断情報を手に入れるから。
Windowsプラットフォームでの起動法
- まずはJDKが正確にインストールしたこととJavaが環境変数に追加したことを確保する
- ダブルクリックPRM解凍ディレクトリ下のbat

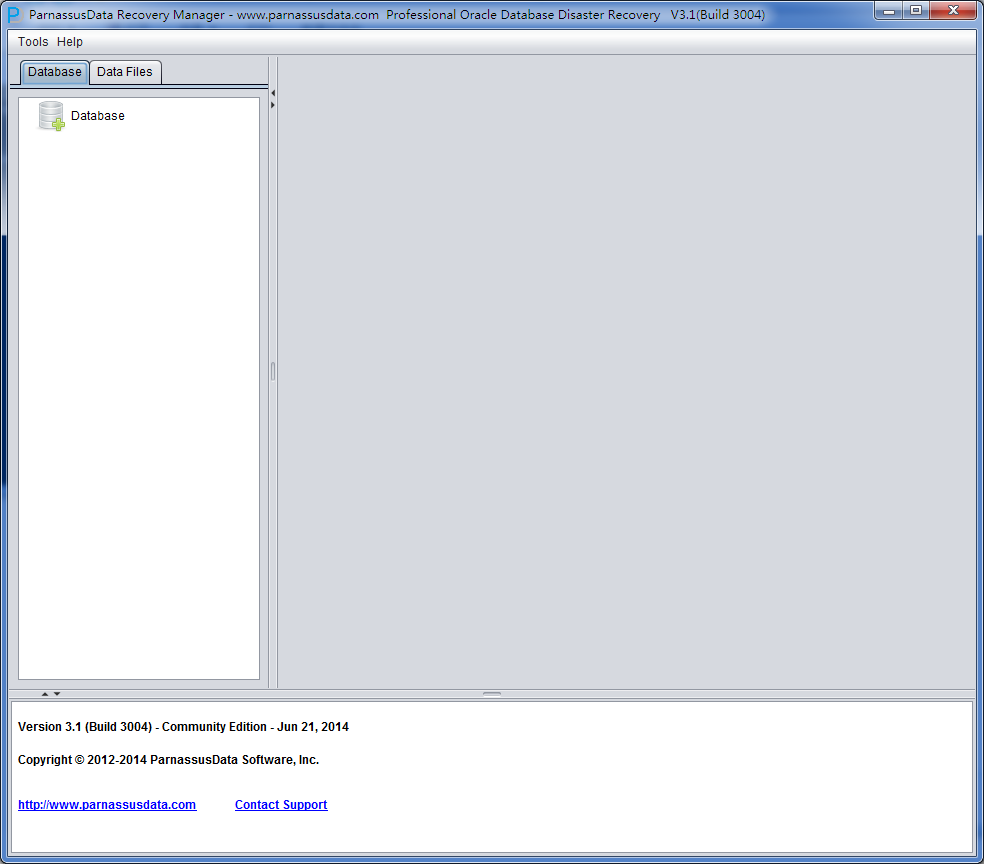
そして、prm.batがバックグラウンドでPRMを起動する。
同時にPRMグラフィカルメインインターフェイスを起動する
- Linux/Unix環境での起動法
- まずはJDKが正確にインストールしたこととJavaが環境変数に追加したことを確保する
- CdはPRMのディレクトリにある、そして./prm.sh起動プログラムのメインインターフェイスを実行する。
PRMのライセンス登録
ParnassusData Recovery Manager(以下略してPRM)はビジネス用ソフトウェアである。ParnassusDataはユーザーがPRMをテストするや勉強するために、コ ミュニティ版を提供している。(コミュニティ版のASM clone機能はなんの限りもなく、今後コミュニティ版ももっと無料機能を追加する。)
なんの限りもなく、自由自在にPRM Oracleデータベースリカバリーソフトを運用したいには、該当するライセンスを購入する必要がある、いま 二種のLicenseタイプを提供している:Standard EditionとEnterprise Edition、詳しい内容はこちら:

| Community Edition | Enterprise Edition | Enterprise service | |
| free |
$1500
PER DATABASE |
応相談 | |
| 支持しているデータベースの大きさ | 一万行 | 限りなし | 限りなし |
| ASM機能を支持しているか否か | YES | YES | YES |
| 電話相談や有料現場サポート | NO | YES | YES |
| DOWNLOAD | BUY NOW | BUY NOW |
ユーザーはParnassusData公式サイトhttp://www.parnassusdata.com/でPRM Licenseを購入することができる。購入する時に、リカバリーしたいデータベースの名前、つまりDBNAMEを入力する必要があって、支払いを完了してから、メールを受信する。そのメー
ルの内容は前に入力したDBNAMEと該当するLicense Keyです。
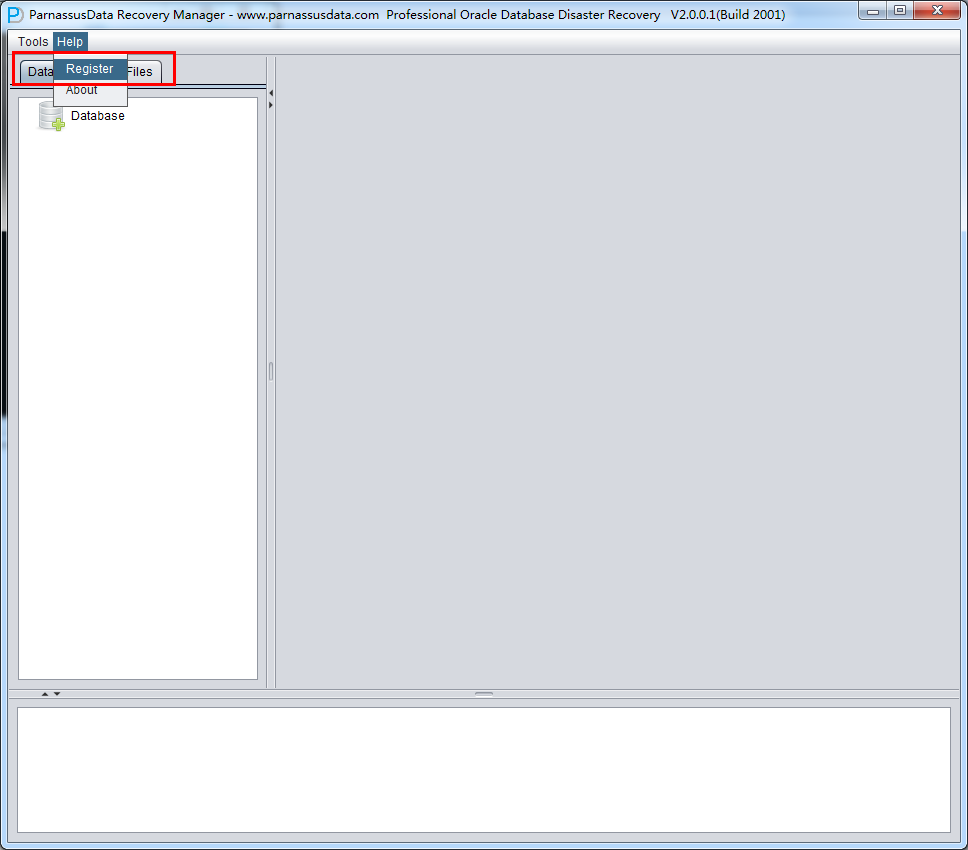
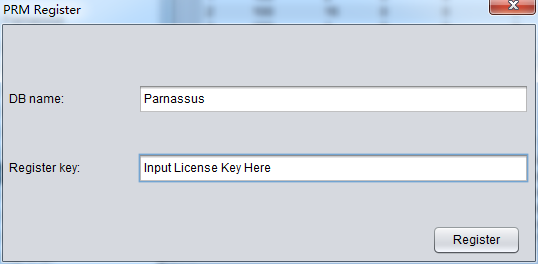
ユーザーがLicense Keyを手に入ってから、ソフトでRegisterをとうろくする。具体的使用法はこのとおり:
- メニューバーHelp => Register
- DB NAMEと先受信したLicense Keyを入力し、RegisterをクリックしてOKです
今後PRMを再起動する際に自動的にLicense登録情報を検出し、一度登録したら、繰り返し登録の必要はない。
異なるOracleデータベーストラブルのリカバリー実行例
リカバリーシーン1 ミスでテーブルをTruncateした時の通常リカバリー
D会社の業務メンテナンス技術者は製品データベースをテスト環境として、あるテーブルの全てのデータをTRUNCATEした。DBAはリカバリーし てみたが、最新なバックアップが使えなくなったことに気づき、バックアップから該当するテーブルの記録をエクスポートできなかった。そのとき、DBAは PRMを採用し、TRUNCATEしたデータをリカバリーすることにした。
その環境で、全てのデータベースファイルは使用可能で健全のため、ユーザーはディクショナリーモードでシステムテーブルスペースのファイルとTRUNCATEDされたテーブルのファイルををロードするだけでOKです。
|
create table ParnassusData.torderdetail_his1 tablespace users as
select * from parnassusdata.torderdetail_his;
|
PRMを起動し、Tools => Recovery Wizardを選択する。
Nextをクリックする。
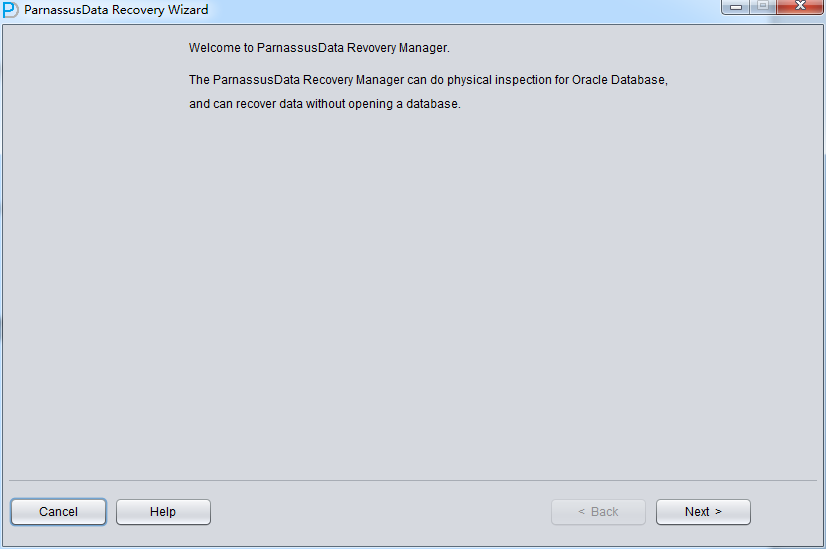
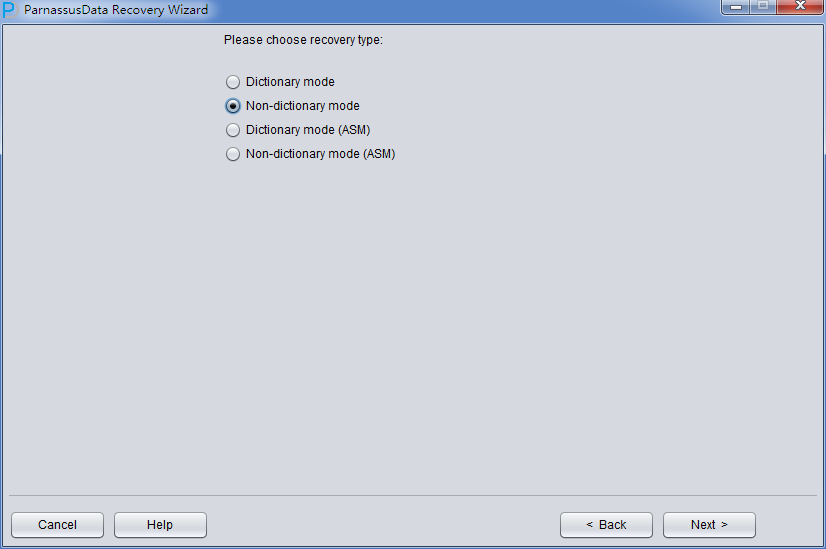
このTRUNCATEシーンではASMストレージを選んでいないため、ディクショナリーモード(Dictionary Mode)だけを選んでいればいい。
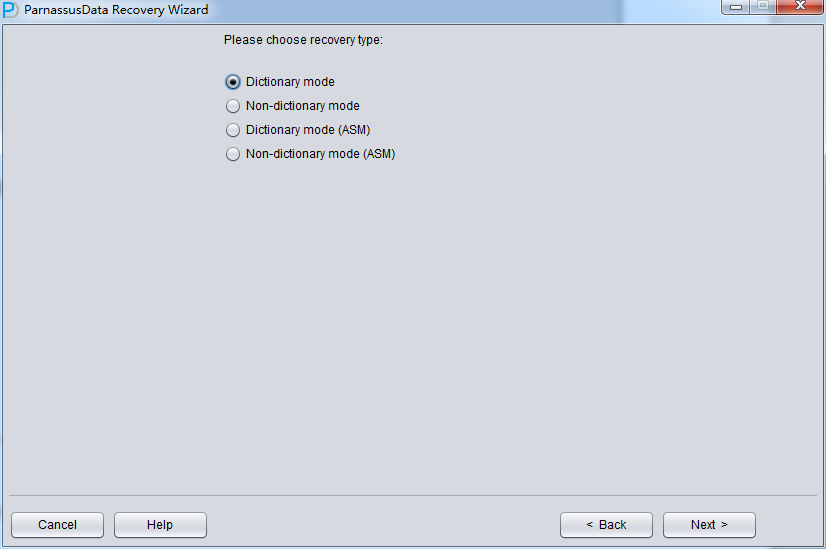
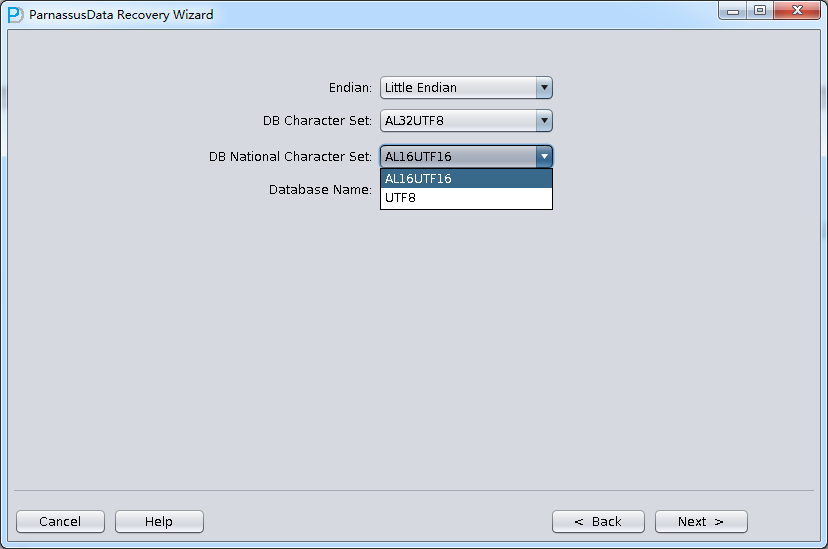
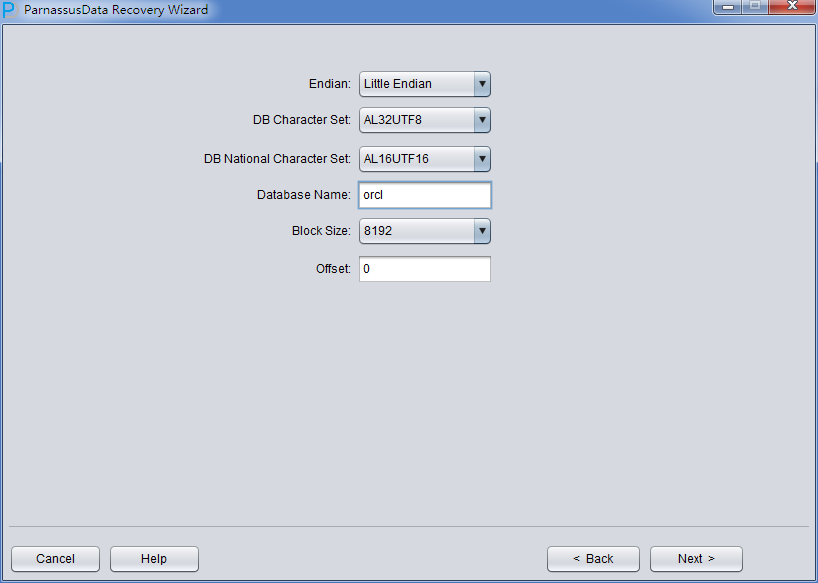
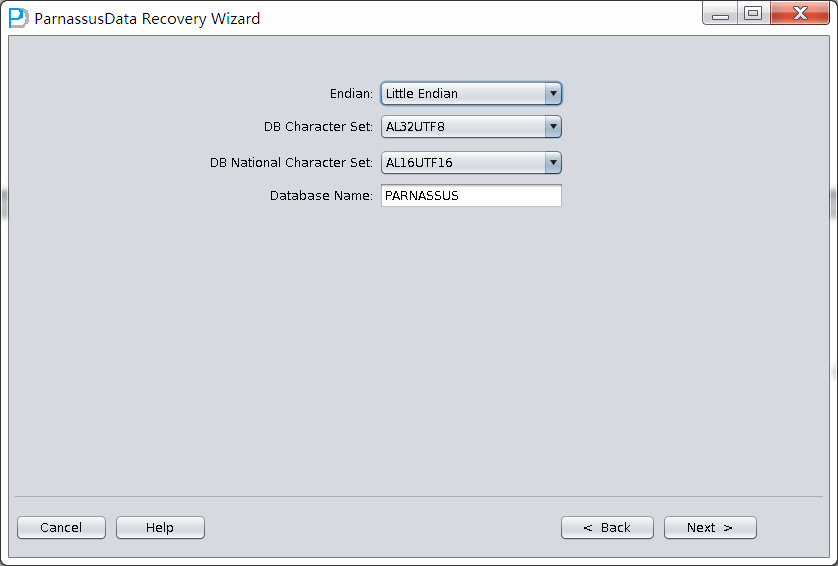
次のステップで、いくつのバラメタを選択する必要がある:EndianエンディアンとDB NAME
Oracleファイルはオペレーションシステム(OS)によって、違ったEndianエンディアン形式を採用し、エンディアンと該当するプラットフォームが以下ご覧のとおり:
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
例えば、伝統的なUnix AIX-Based Systems (64-bit) 、HP-UX (64-bit)ではBig Endianをつかっている、ここではBig Endianに変更する:
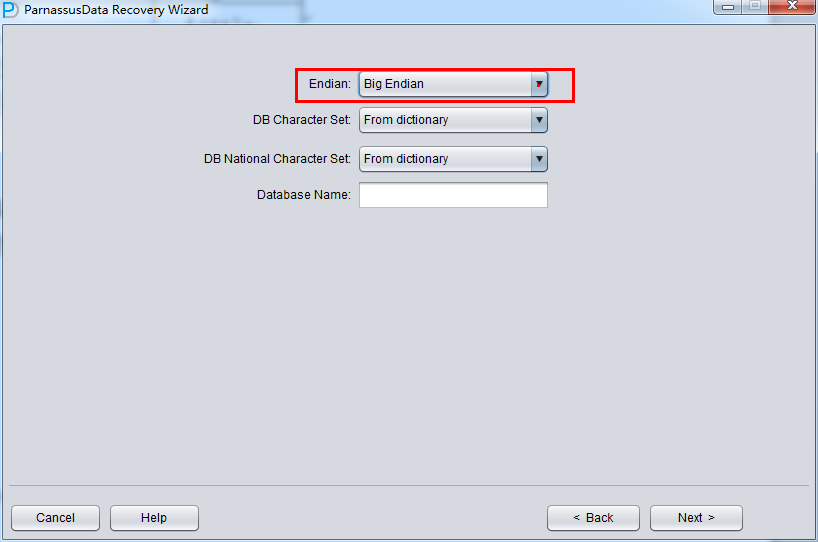
さもないと、Linux x86-64 、WindowsではデフォルトのLittle Endianままになる。
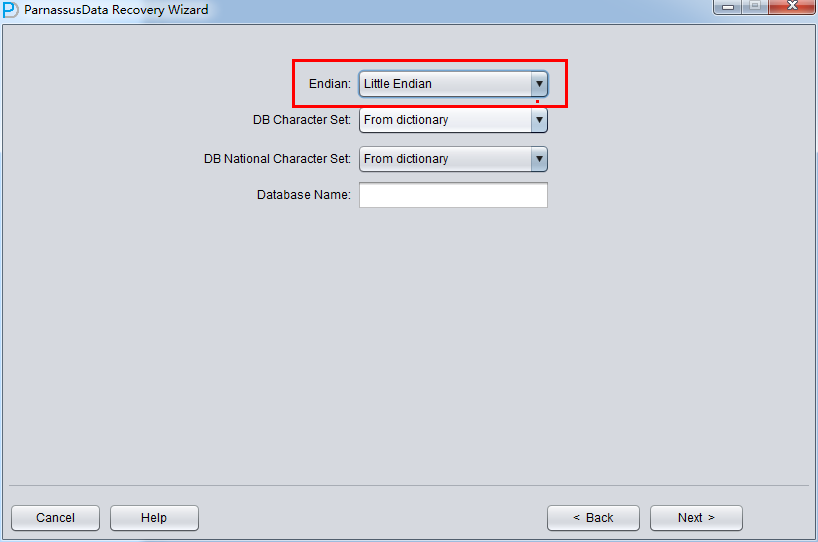
注意事項:もし、ファイルがもともとはAIX(つまりBig Endian)に生成するなら、都合のいいため、これらのファイルをWindowsサーバへコーピーし、PRMによってデータをリカバリーするなら、元のBig Endian形式に選ぶ必要がある。
ここでは、例のファイルがLinux x86にあるため、EndianをLittleに変更し、Database name入力する。(ここに入力したデータベース名は名前だけで、データベースホントのDBNAMEにいみしていない、PRMlのLicense検出メカ ニズムがつかっているのはここに入力したDatabase Nameじゃなく、ホントのDBNAMEをつかっているから):
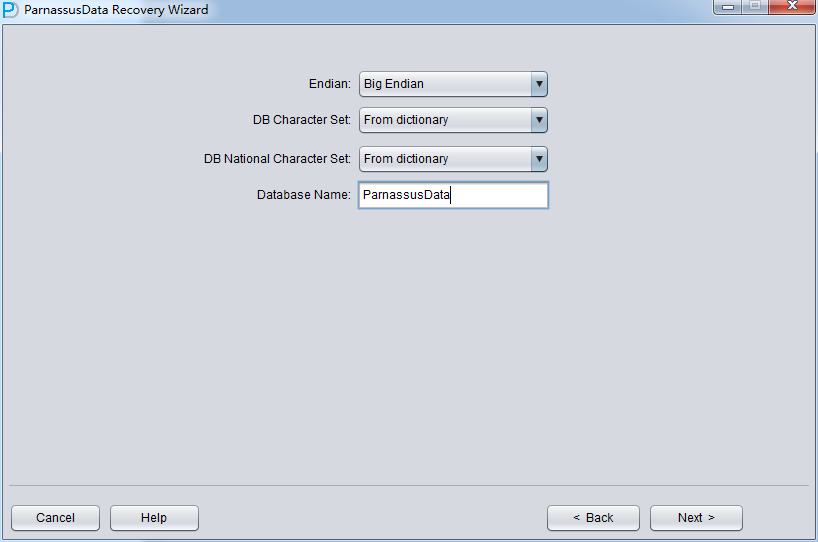
Nextをクリックする。
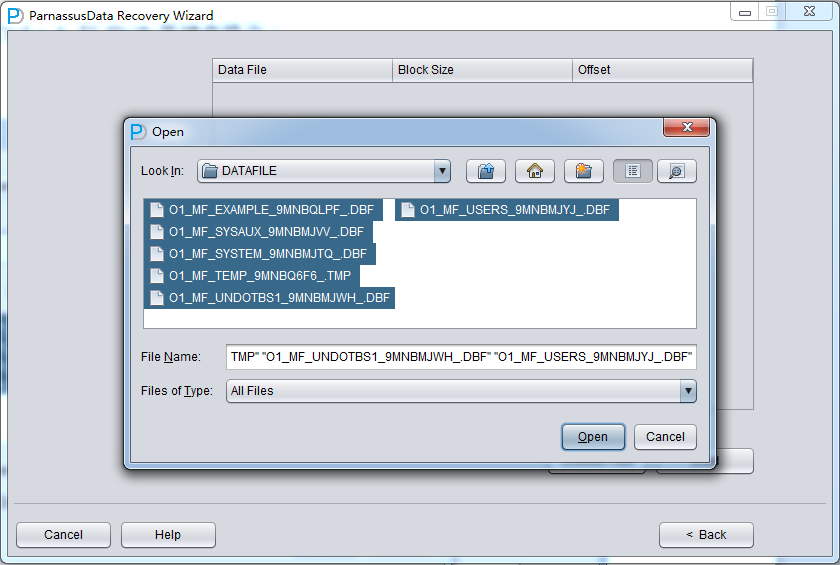
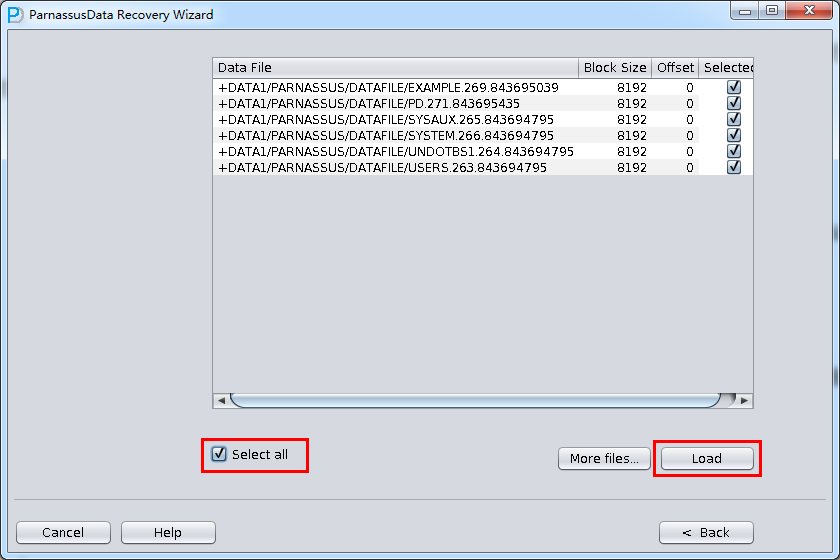
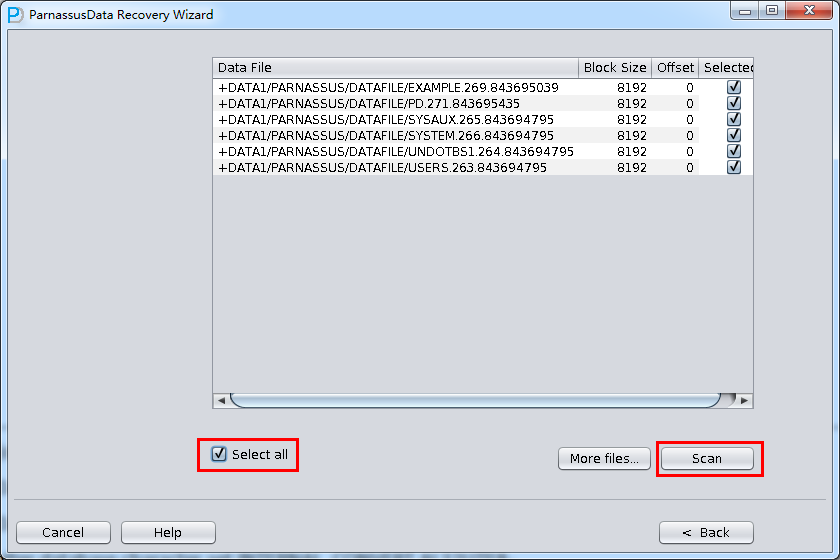
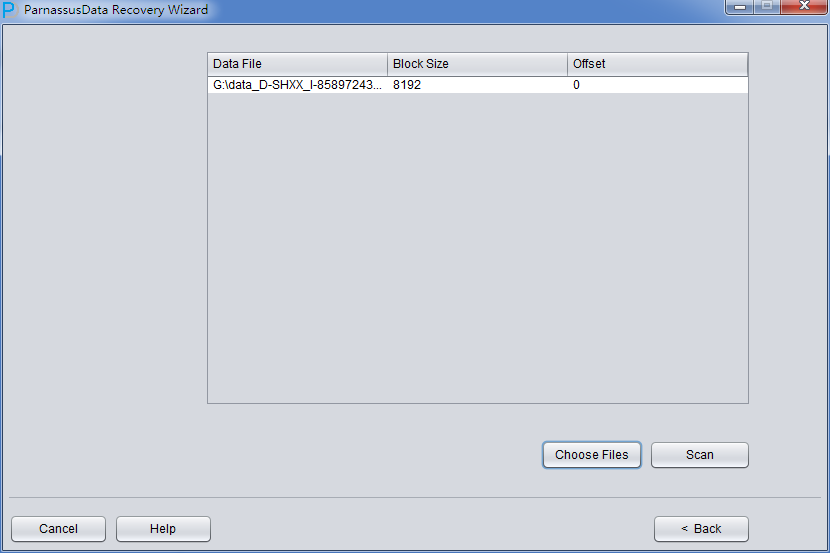
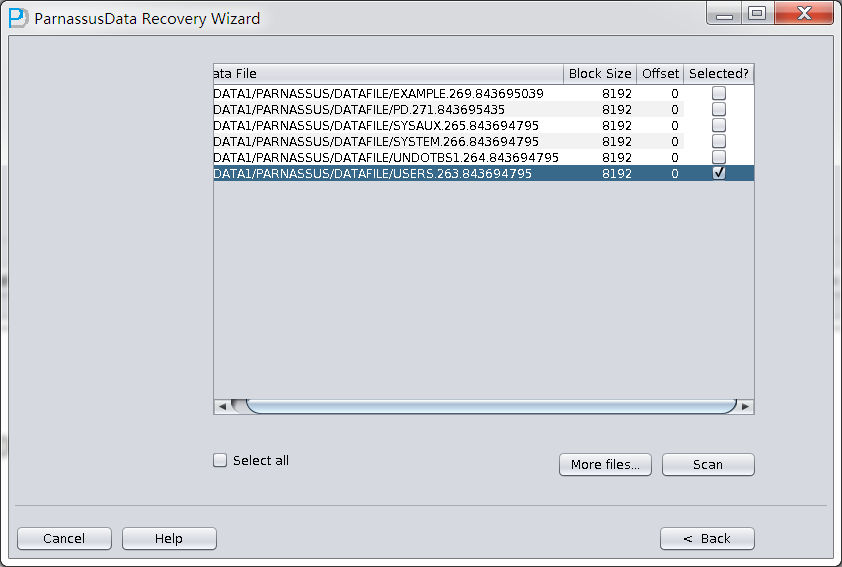
Choose Filesをクリックして、一般的には、データベースが大きくなければ、データベースにある全てのファイルを選定する必要がある。データベースが大きで、 そしてデータテーブルがどこのフィイルにあるかをしっていれば、SYSTEMテーブルスペースのフィイルとデータテーブル(必要)を含むフィイルしかえら べない。
注意:ChooseインターフェースではCtrl + A とShiftなどキーボード操作を支持している。
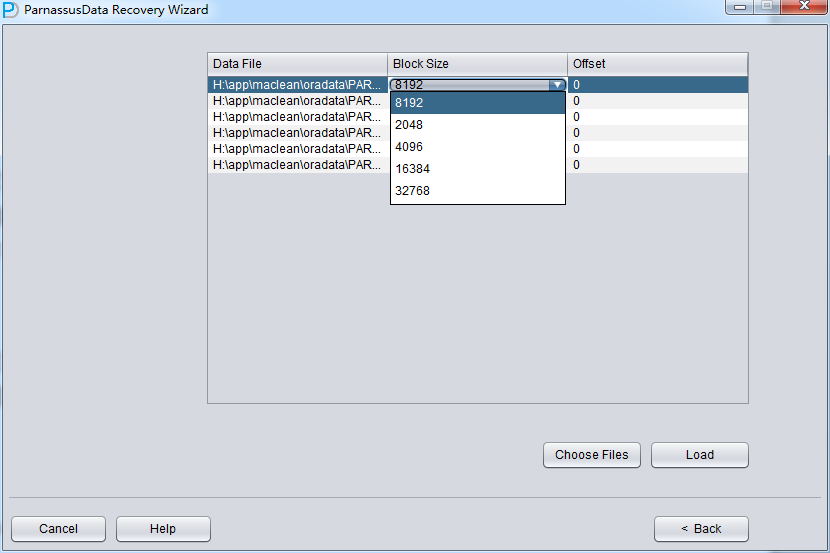
後で、特定のファイルのBlock Sizeを指定する。つまり、Oracleデータブロックの大きさをしていする必要がある。ここは実際に応じて変更すればいい。例えば、 DB_BLOCK_SIZEは8Kだが、一部のデータブロックテーブルスペース指定が16Kから、テーブルスペースが8Kじゃないデータブロックの BLOCK_SIZEを変更すればいい。
ここのOFFSETバラメタは主にRAWデバイスにファイルを格納するときにたいおうするためのバラメタです。
もし、RAWデバイスフィイルをつかっているときにOFFSETをわからなければ、$ORACLE_HOME/binのdbfsizeツールを使って確認すればいい。したのきいろの部分が示したように、ここのRAWデバイスは4KのOFFSETをもっている。
|
$dbfsize /dev/lv_control_01
Database file: /dev/lv_control_01 Database file type: raw device without 4K starting offset Database file size: 334 16384 byte blocks |
このシーンで全てのファイルは8KのBLOCK SIZE、そしてファイルシステムはOFFSETがないので、Loadをクリックする。
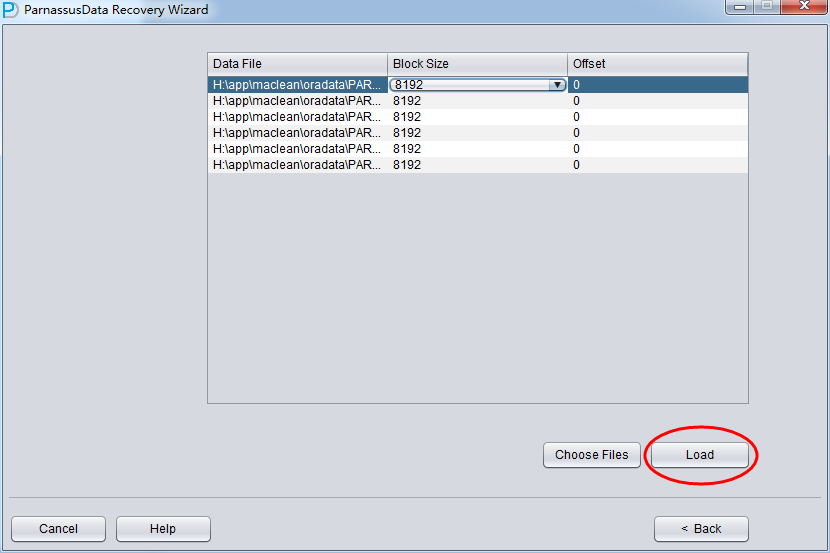
Loadステップに、PRMはSYSTEMテーブルスペースでOracleデータディクショナリー情報を読み取り、自らのDerbyでデータディクショナリー新規することによって、PRMがOracleデータベースにあるさまざまなデータを操作できる。
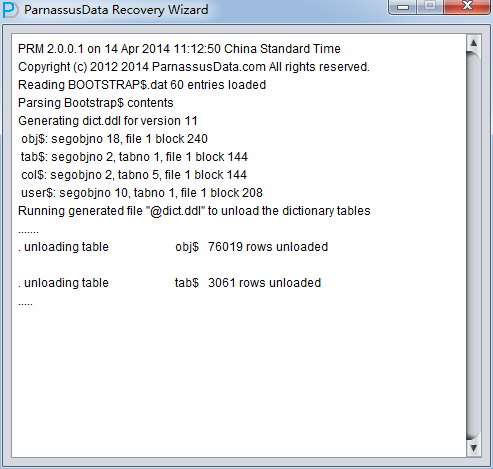
Load完成したあと、バックグラウンドでデータベース・キャラクタ・セットと各国語キャラクタ・セットをエクスポートする。
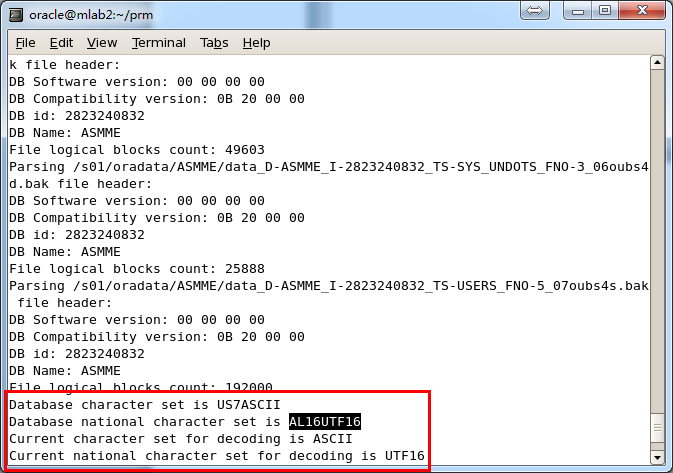
PRMは多国言語およびOracleデータベースマルチキャラクタセットを支持しているが、PRMでデータをリカバリーしたいオペレーションシステ ムを事前に該当するLanguage Packsをインストールしないといけない。たとえば、Windowsオペレーションシステムでは中国語Language Packsをインストールしていないが、ORACLEデータベース・キャラクタ・セットがオペレーションシステムから独立しているから、このシーンでつ かっているORACLEデータベース・キャラクタ・セットがZHS16GBKキャラクタ・セットで、オペレーションシステムは中国語を支持していないです が、このシーンでサーバに配置していないOracleクライアントは影響をうけず、正確にデータをしめすことができる。
でも、PRMをつかうにはPRMでデータをリカバリーしたいオペレーションシステムが事前に該当するLanguage Packsをインストールする必要がある。例えば、ユーザーがZHS16GBKの中国語キャラクタ・セットデータベースをリカバリーしたいとき、オペレー ションシステムが中国語Language Packsをインストールした必要がある。
Linuxにもfonts-chinese中国語フォントパッケージをインストールする必要がある。
Load完成したあと、PRMインターフェースの左側にはデータベースユーザーPacketによる樹形図が現れる。
USERSをクリックし、いろんなユーザー名がでる。例えば、ユーザーがPARNASSUSDATA SCHEMAの下のテーブルをリカバリーしたいが、PARNASSUSDATAをクリックして、テーブルをダブルクリックする。
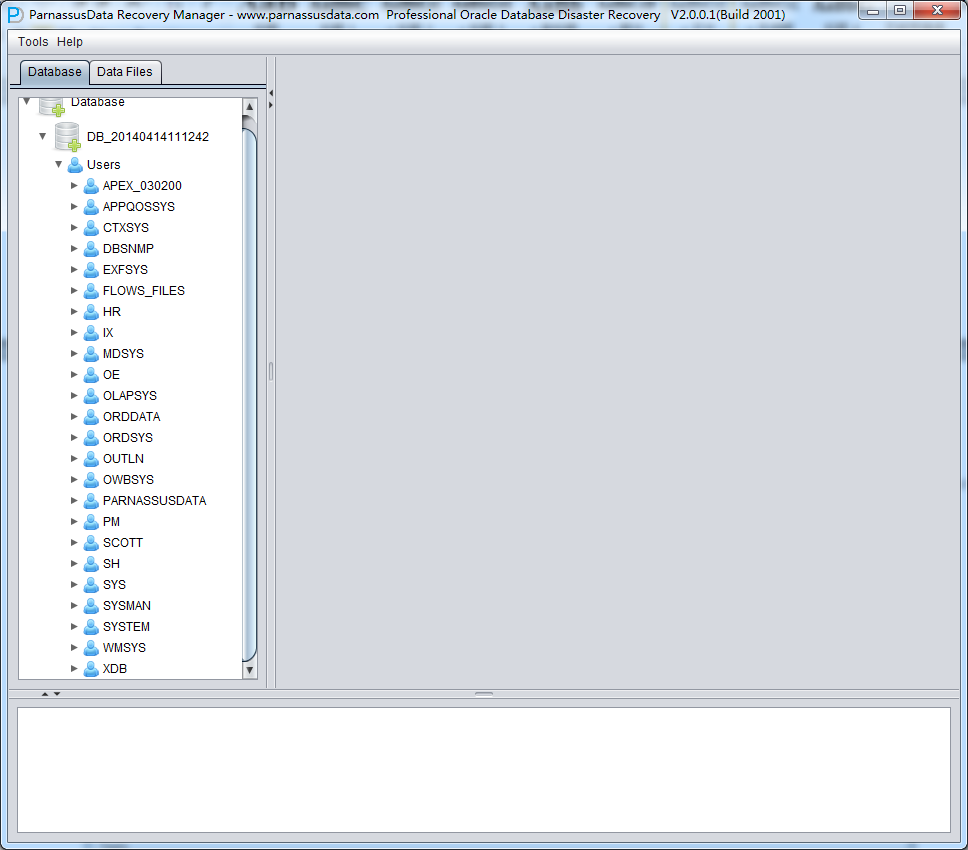
該当するTORDERDETAIL_HIS表がその前にTRUNCATEDされたから、ダブルクリックしてもデータを示せない。そのとき、テーブルにマウスの右ボタンでUnload truncated dataをクリックする。
PRMはそのテーブルを含むテーブルスペースをスキャンして、truncatedされたデータを抽出できる。
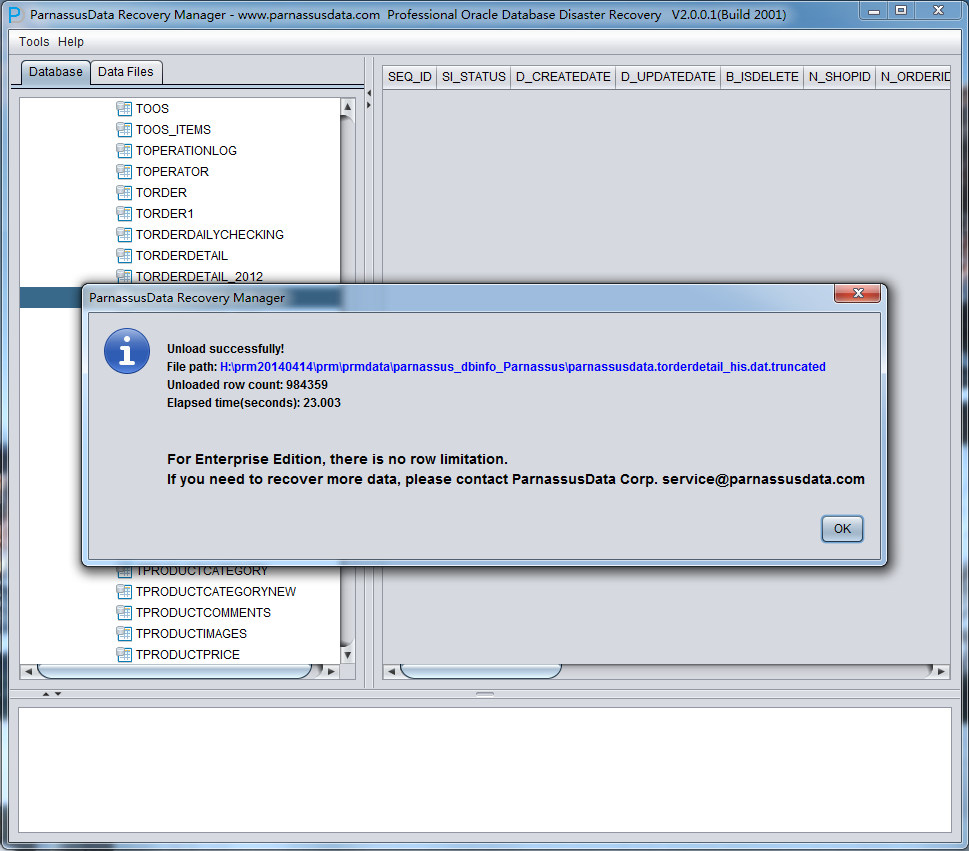
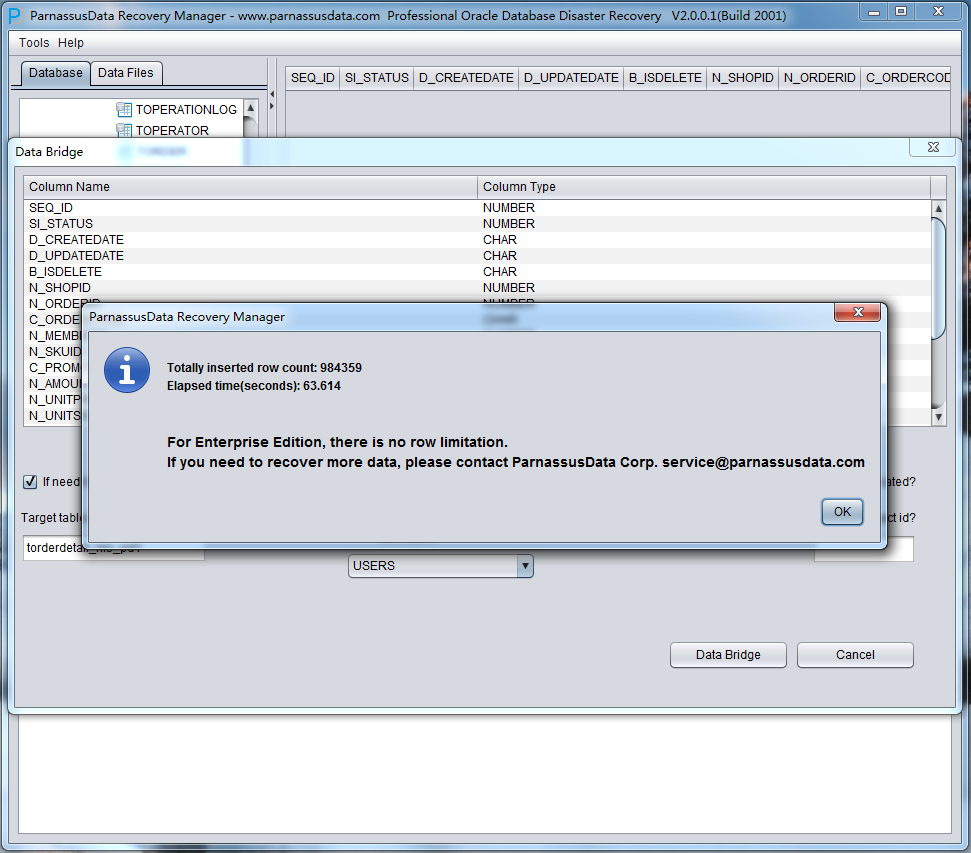
上のグラフのように、TRUNCATEされたTORDERDETAIL_HISテーブルからすべての984359の記録、指定されたパスに格納する。
|
$ cd /home/oracle/prm/prmdata/parnassus_dbinfo_PARNASSUSDATA/
$ ls -l ParnassusData* -rw-r–r– 1 oracle oinstall 495 Jan 18 08:31 ParnassusData.torderdetail_his.ctl -rw-r–r– 1 oracle oinstall 191164826 Jan 18 08:32 ParnassusData.torderdetail_his.dat.truncated
$ cat ParnassusData.torderdetail_his.ctl LOAD DATA INFILE ‘ParnassusData.torderdetail_his.dat.truncated’ APPEND INTO TABLE ParnassusData.torderdetail_his FIELDS TERMINATED BY ‘ ‘ OPTIONALLY ENCLOSED BY ‘”‘ TRAILING NULLCOLS ( “SEQ_ID” , “SI_STATUS” , “D_CREATEDATE” , “D_UPDATEDATE” , “B_ISDELETE” , “N_SHOPID” , “N_ORDERID” , “C_ORDERCODE” , “N_MEMBERID” , “N_SKUID” , “C_PROMOTION” , “N_AMOUNT” , “N_UNITPRICE” , “N_UNITSELLINGPRICE” , “N_QTY” , “N_QTYFREE” , “N_POINTSGET” , “N_OPERATOR” , “C_TIMESTAMP” , “H_SEQID” , “N_RETQTY” , “N_QTYPOS” )
|
データをソーステーブルにロードする(注意:元の環境を上書きされないように、SQLLDRコントロールフィルタを変更するときに、一時的なテーブルをロードしてください。
|
$ sqlldr control=ParnassusData.torderdetail_his.ctl direct=yUsername:/ as sysdba
以上はsqlldrでリカバリできたデータの実例です。
Minusによって、リカバリしたデータを比べることもできる select * from ParnassusData.torderdetail_his minus select * from parnassus.torderdetail_his;
no rows selected
|
テスト中、TRUNCATEと元のテーブルと比べて、記録が完全に同様に見える。
それは、PRMはTRUNCATEテーブルの記録をリカバリできたから。
リカバリシーン2 過ちでTruncateされたテーブをバイパスリカバリ
シーン1では、通常のunload+sqlldr方法を採用したが、実際使用中、私たちはかなり工夫して設計できたDataBridgeデータバイパスモードを勧めます。
なぜデータバイパスモードを使う必要があるでしょう?
通常のunload+sqlldr方法はソースデータ、抽出するデータ、および目標のデータを格納するスペースが必要、つまり、もとの空間の二倍を要求する。バックアップのスペースさえ用意できない企業に対して、これはかなり厳しい要求だと思います。
データバイパスとunload+sqlldrモードの一番大きな違いはデータバイパスはソースリポジトリからデータを抽出し、目標データベースへ転移して、もとのフィルタシステムに抽出データを格納する必要はない。
データバイパスによって、目標データベースに転移されたデータは元々構造化されたから、SQLで一貫性と整合性をかくにんできる。
データバイパスの目標データベースは異なるマシンにある場合は、ソースデータベースに対して、読み取りしかできない、読み書きIOは二つのマシンに配置し、PRMリカバリスビートがよく速くなる。
ユーザーリカバリしたいのはTruncateデータの場合に、バイパスによってすぐにソースデータベースに戻れる、リカバリ作業はマウスをクリックするだけですませる。
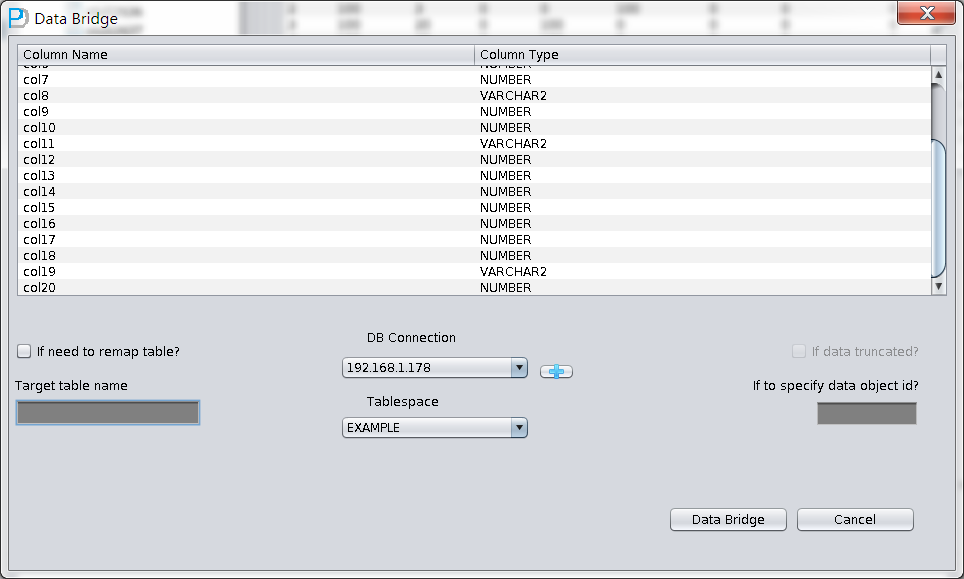
データバイパスモードを使うには、通常モードと同じ、左側の樹形図に必要なテーブルを選んで、右ボタンでDataBridgeオプションをクリックする。
初めてデータバイパスモードを使うときに、まずは目標データベースとつながる情報を入力する必要がある。これはSQLDEVELOPERに Connectionを構造する作業に似ている。これは目標データベースのホスト、ポート、Service_Nameおよびユーザー登録情報も含んでい る。ここに入力したユーザー情報は、後でデータバイパスを使う目標データベースのユーザーのことだから、つまり、ソースリポジトリから抽出したテーブルは 指定された目標データベースユーザーへ転移する。
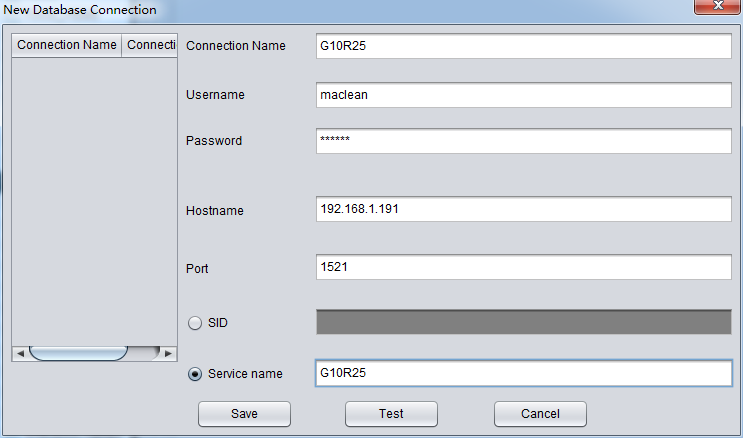
このように、G10R25というリンクを構造した、ユーザーはmaclean、該当するoracle Easy Connection接続文字列は192.168.1.191:1521/G10R25。
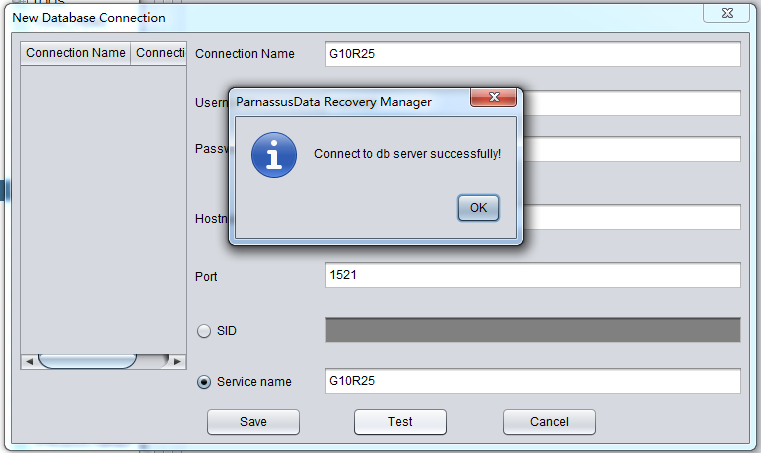
以上のようなデータベース情報入力を完成したら、Testボタンをクリックして、リンクオプションが使えるか否かを確認できる。もし、“ Connect to db server successfully “が戻ってきたら、いまリンクが使えるということを意味する。そのままSaveをクリックして、セブすればいい。
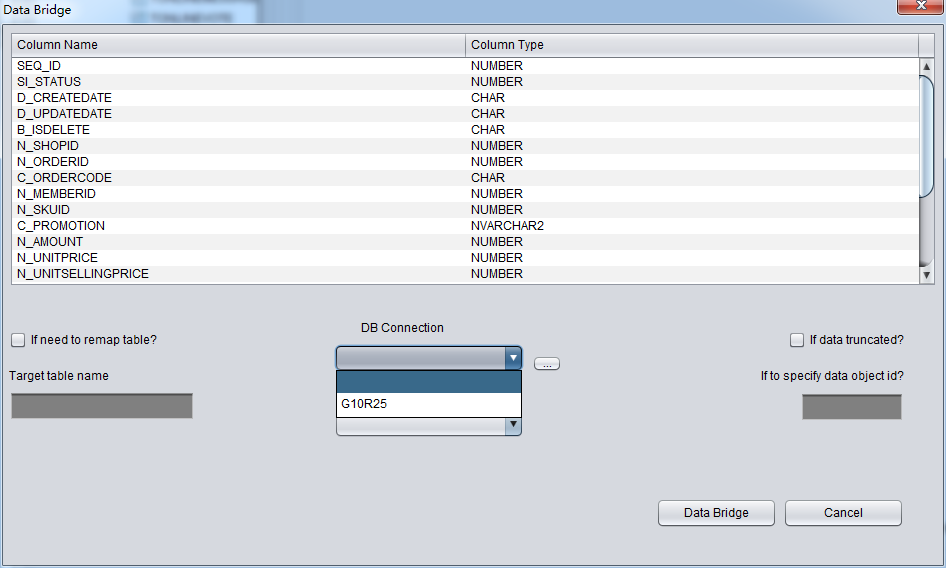
セブできたら、DataBridgeインタフェースに入って、まずはDB Connectionドロップダウンリストに、先に追加したConnection G10R25を選択する:
DB Connectionドロップダウンリストに必要とするデータベースリンクが現れていないなら、DB connectionのそばにある「…」ブタンを押してDB Connection:を追加してください
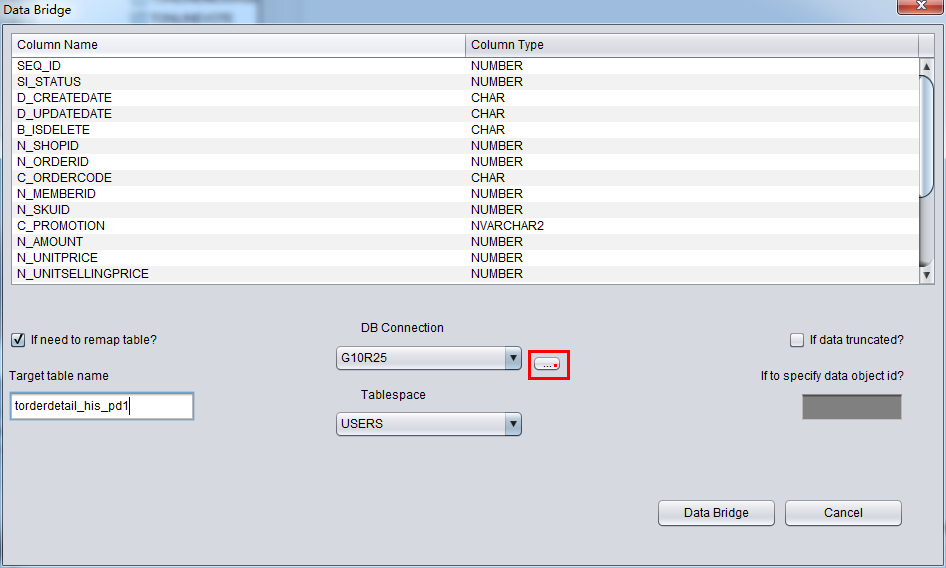
DB Connectionを正確に選んでいたら、Tablespaceドロップダウンリストが使えるようになる、ふさわしいテーブルスペースを選んでください。
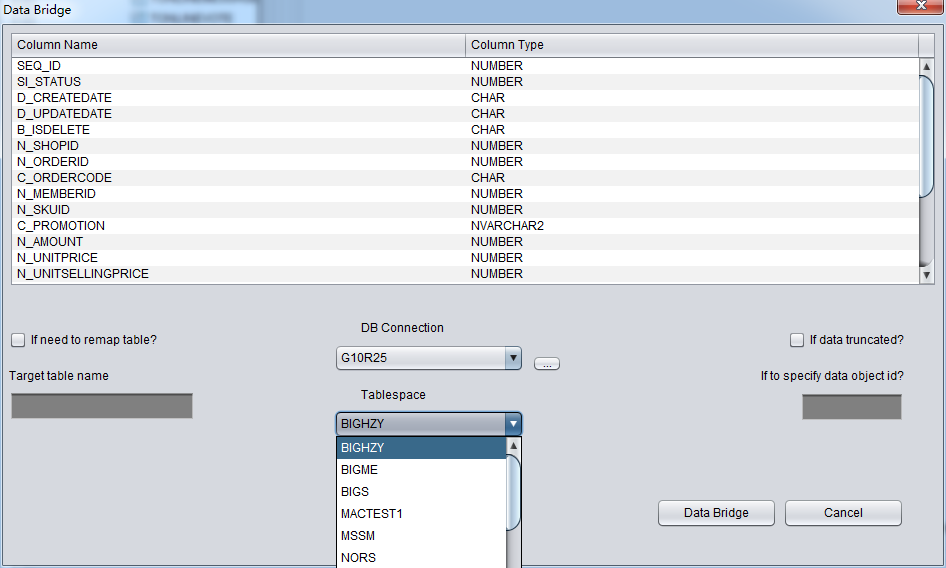
Data Bridgeを使って、truncateをリカバリするときに、以下のようなことを注意してください:ソースリポジトリからtruncateデータをリカ バリするときに、databridgeオプションを使って、データをソースデータベースへ伝送する場合(ソースリポジトリじゃなければ問題ない)、 Databridgeを新規テーブルにインサートするアドレスはソースデータベースにtruncateされたアドレスにしないでください。さもなければ、 truncateされたデータをリカバリしながら、リカバリされたばかりのデータが上書きされることになる。こういう時に上書きされたデータがリカバリで きないので、ご注意をください。databridge+を使ってデータをソースデータベースにリカバリするとき、およびdatabridgeにテーブルス ペースを指定する場合、ぜひ、リカバリしたいテーブルスペースをつかわないでください。
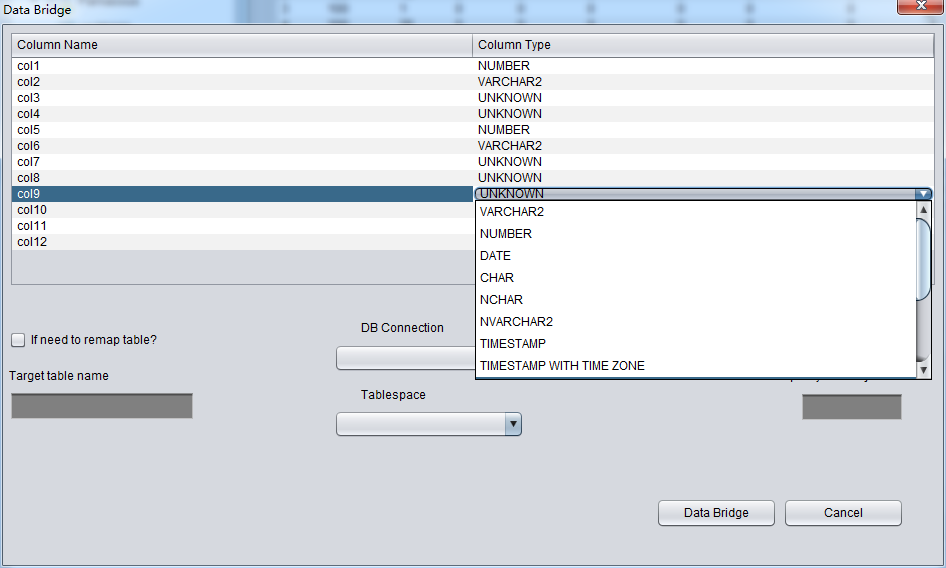
ユーザーはソースリポジトリから目標リポジトリへ伝送するテーブルの名前のマッピングを変更するか否かを選択できる。例えば、ソースリポジトリであ るテーブルがTruncateされた、いまはDataBridgeにより、データをソースリポジトリへリカバリするが、元の名前をつかいたくないで、ほか の名前で格納したいとき、“if need to remap table”を選んでふさわしい名前を入力すればいい:
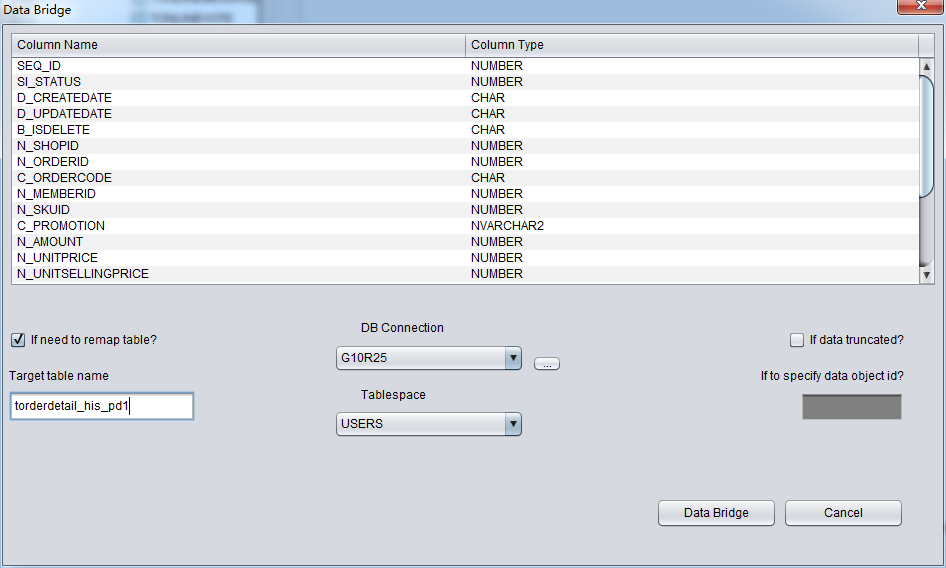
1.目標リポジトリに該当するテーブルの名前がすでに存在している場合に、PRMはテーブルを再構造することじゃなく、既存するテーブルを元にリカバリしたいデータをインサートする。テーブルはもう構造したから、指定したテーブルスペースが無力化になる。
2.目標リポジトリに該当するテーブルの名前がまだ存在していない場合は、PRMが指定したテーブルスペースにテーブルを構造し、リカバリしたいデータをインサートしてみます。
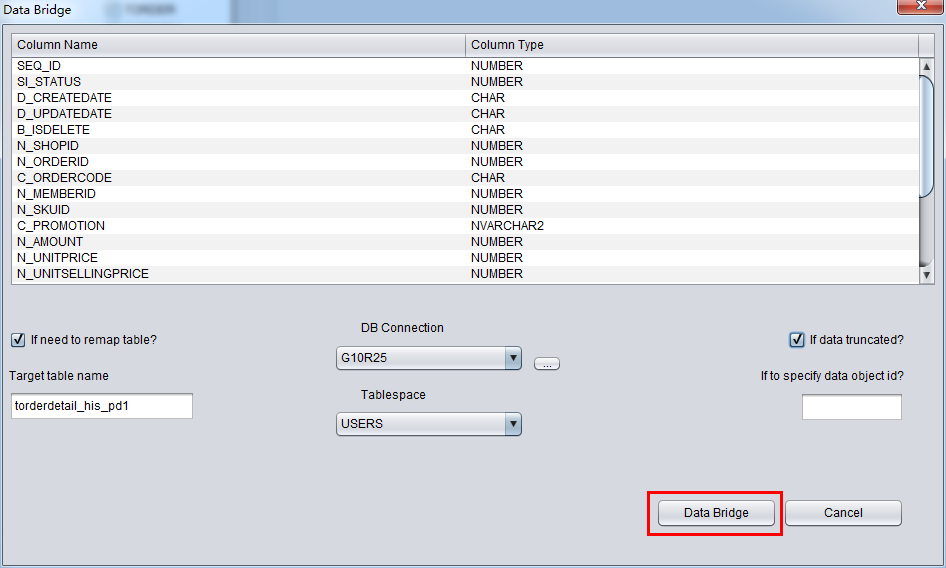
このシーンで私たちがリカバリしたのはTruncateされたデータで、“if data truncated”を選択する必要がある。さもなければ、PRMは通常のモードでデータを抽出するから、Truncateされたデータが見えなくなる。
Truncateデータの原理は、OracleがデータディクショナリーとSegment HeaderにテーブルのData Object IDを更新するが、実際データに一部のブロックが更新されない。データディクショナリーとセグメントヘッダーのDATA_OBJECT_IDがあとのデー タブロックにあるが一致していないため、Oracleサビースプロセスがテーブル全体のデータを読み取るときに、TRUNCATEされたが、まだ上書きさ れていないデータは読み取れない。
PRMは自動スキャンによって、データセグメントヘッダー(Segment Header)がTRUNCATEされた後のデータブロックはTRUNCATEされた前のDATA_OBJECT_IDを判断し、ディクショナリーにテー ブルフィールドの定義と自動獲得したDATA_OBJECT_IDによって、データを抽出する。
そして、”if to specify data object id”というインプットボックスが存在している。これによって、ユーザーがリカバリしたいデータのData Object IDを指定できる。Truncateデータをうまくリカバリできなかったときに限って、ParnassusDataの技術サポートを元に、指定してくださ い。それ以外、何の数値を指定する必要がない。
以上のように、DataBridge配置を正確に配置できたら、データバイパスを実行できる。DataBridgeボタンをクリックしてください:
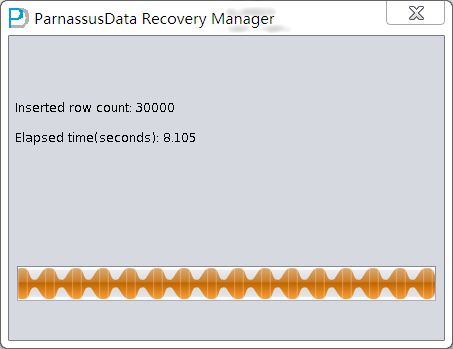
データバイパスが完成したら、伝送できたデータ行数と経過時間を示される。
リカバリシーン3 Oracleデータディクショナリーがダンメージを受け、データベースが起動できない
D社のDBAは誤操作でTS$データディクショナリーを削除したため、データベースが起動できない。
|
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 – 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options
INSTANCE_NAME —————- ASMME
SQL> SQL> SQL> select count(*) from sys.ts$;
COUNT(*) ———- 5
SQL> delete ts$;
5 rows deleted.
SQL> commit;
Commit complete.
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down.
Database mounted. ORA-01092: ORACLE instance terminated. Disconnection forced ORA-01405: fetched column value is NULL Process ID: 5270 Session ID: 10 Serial number: 3
Undo initialization errored: err:1405 serial:0 start:3126020954 end:3126020954 diff:0 (0 seconds) Errors in file /s01/diag/rdbms/asmme/ASMME/trace/ASMME_ora_5270.trc: ORA-01405: fetched column value is NULL Errors in file /s01/diag/rdbms/asmme/ASMME/trace/ASMME_ora_5270.trc: ORA-01405: fetched column value is NULL Error 1405 happened during db open, shutting down database USER (ospid: 5270): terminating the instance due to error 1405 Instance terminated by USER, pid = 5270 ORA-1092 signalled during: ALTER DATABASE OPEN… opiodr aborting process unknown ospid (5270) as a result of ORA-1092
|
このシーンでデータディクショナリーは既に壊されたから、データベースを起動するのは不可能だ。
このとき、PRMでデータベースのデータを抽出することができる。具体的な操作はシーン1とほぼ同じ、ユーザーがデータベースにあるすべてのデータベースフィルタを入力しただけでいい。
2.ディクショナリーモードを選んでくださいDictionary Mode
3. BigかLittle Endianを選ぶにはよく考えてください
4.データフィルタを追加してロードをクリックしてください。
5.実際に応じて、テーブルのデータをリカバリしてください。
リカバリシーン4 誤削除とSYSTEMテーブルスペースがなくした。
D社のSAシステム管理員があるデータベースのSYSTEMテーブルスーペスのフィルタを削除したことによって、データベースがうまく起動せず、データを取り出せない。でも、たとえバックアップがなくても、PRMで100%に近いデータをリカバリできる。
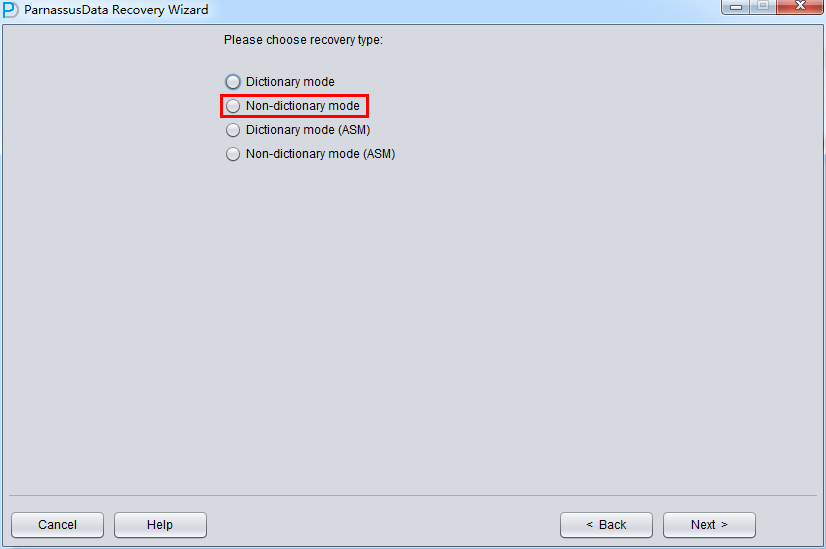
此场景中启动PRM后,进入Recovery Wizard后 选择《Non-Dictionary mode》非字典模式:このシーンでPRMを起動したら、Recovery Wizardに入ったら、Non-Dictionary modeを選んでください:
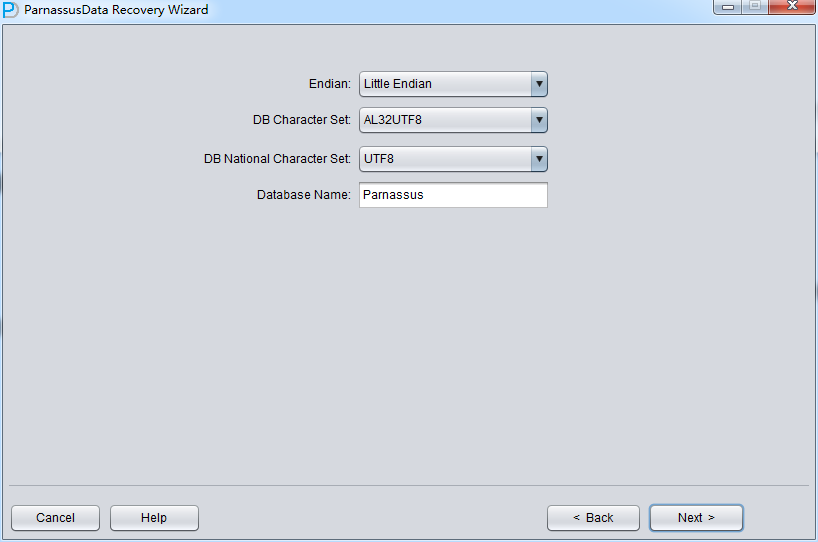
No-dictionaryモードでユーザーが文字セットと各国語キャラクタ・セットを指定する必要がある。システムテーブルスペースをなくした 後、データベース情報の文字セットが正確に獲得できないから、ユーザーの入力が必要になる。正確に文字セットを設置したことと必要な言語パックをインス トールしたことはNo-Dictionaryモードで、順調に多国語を抽出する保障である。
シーン1と同じように、いまユーザーが獲得可能なすべてのフィルタを入力し(一時的なフィルタを含まない)、正確にBlock SizeとOFFSETを設置してください:
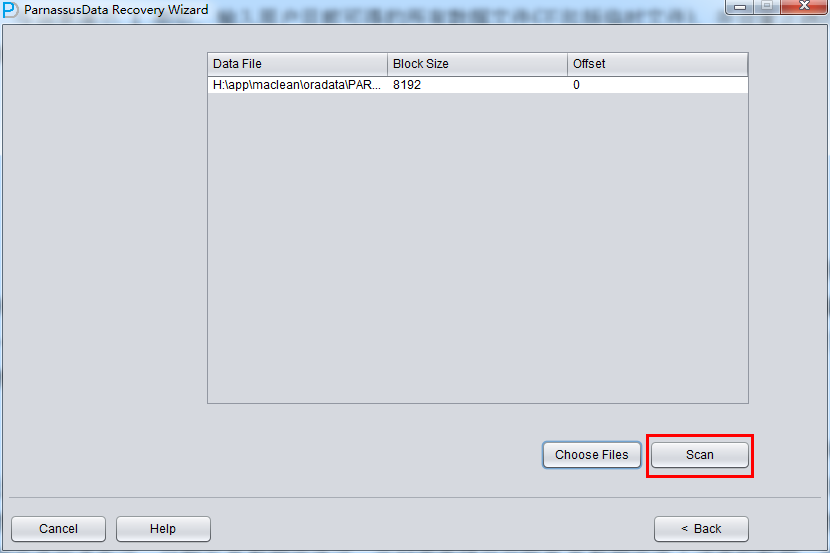
そして、SCANをクリックしてください。SCANの役目はすべてのフィルタのSegment Headerをスキャンし、SEG$.DATとXT$.DATに記録する。Oracleの中で、一つの非パーティション表とパーティション表はテーブル データセグメントのEXTENT MAP情報に該当する、EXTENT MAPによって、そのテーブルにすべての記録を手に入れる。
また、一つの非パーティション表をある二つのフィルタによって構造したテーブルスペースに格納し、そのSEGMENT HEADERと半分のデータがAフィルタに格納し、その
ほかの半分がBフィルタに格納する。だが、ある事情によってSYSTEMテーブルスペースもSEGMENT HEADERを格納したAフィルタもなくし、Bフィルタしか残っていない場合に、ただBフィルタのデータをリカバリしたいとすれば、SEGMENT HEADERに頼らず、BフィルタのEXTENT MAPの情報に頼るしかない。
SEGMENT HEADERに基づく和EXTENT MAPデータのNO-Dictionaryモードのリカバリ需要を同時に満たすために、SCAN操作はここでSEG$.DATとEXT$.DATに書き込 み、(テキストフィルタは診断しやすくなるため、すべてのプログラムはPRM自身が持ち込むDERBYに頼っている。)そしてDERBYデータベースに記 録する。
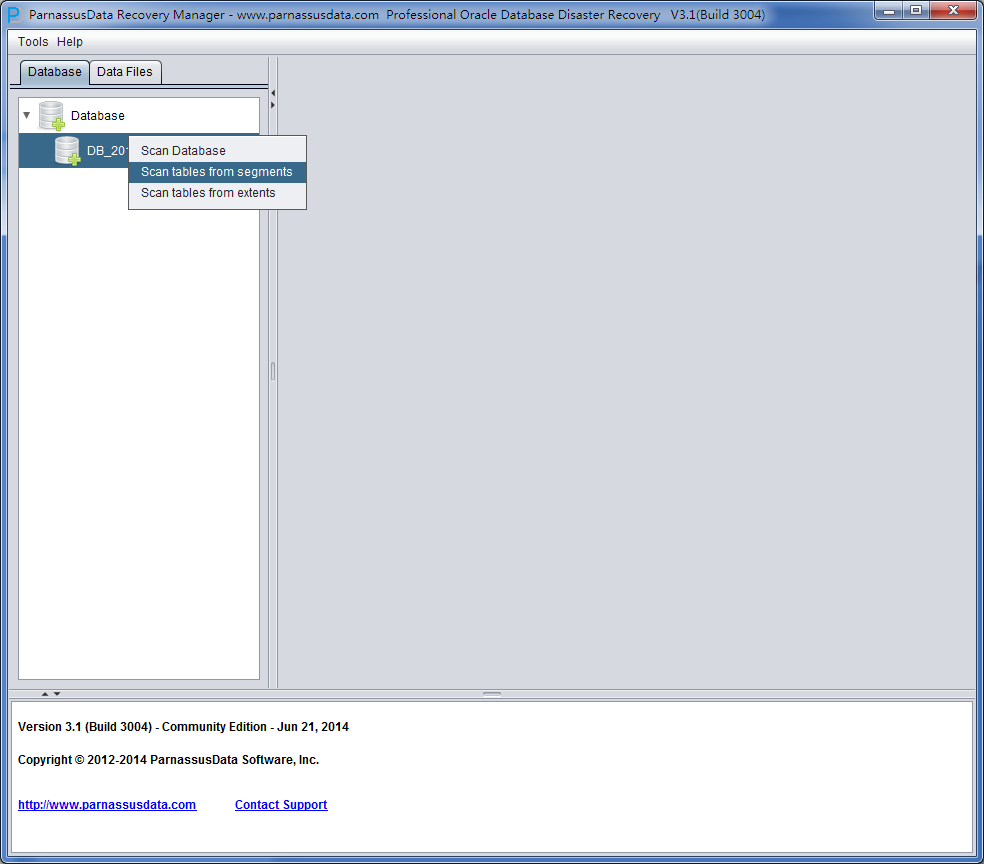
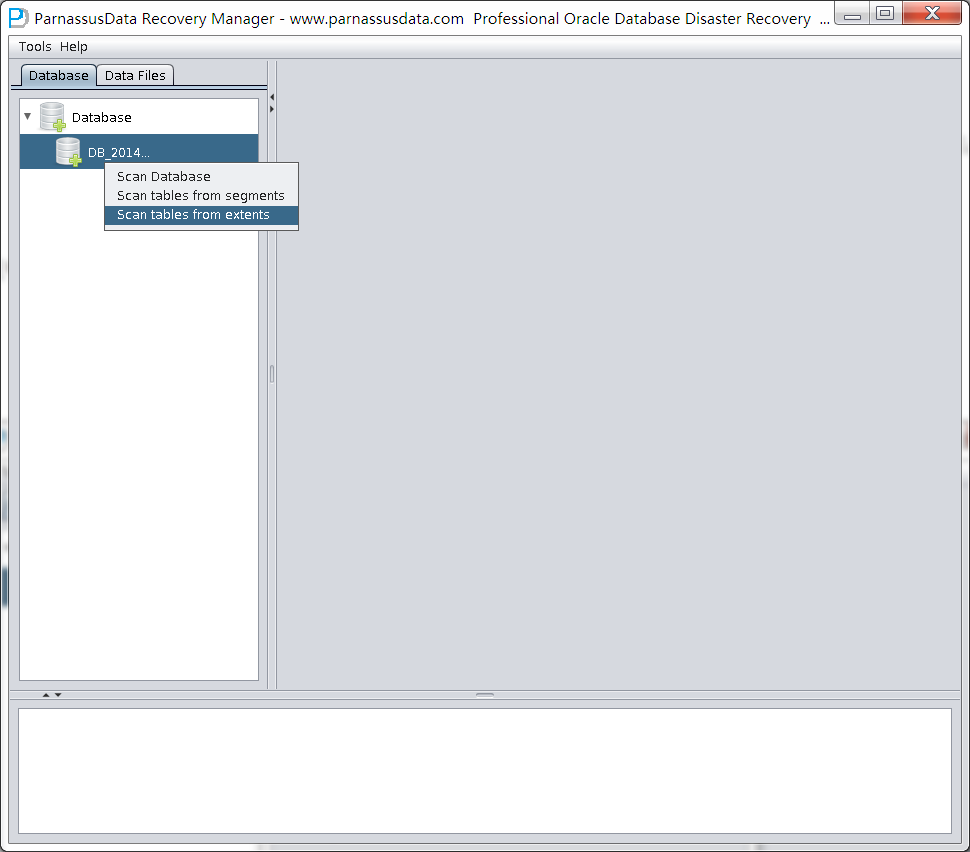
SCANを完成したら、インタフェースの左側にデータベースアイコンが現れる。
この時、二つのバッタンを選べる。:
- Scan Tables From Segments、このバッタンは:
システムテーブルスペースをなくしたが、すべての応用データテーブルスペースが存在している場合に適応している。
- Scan Tables From Extents
DictionaryモードのTruncateテーブルデータリカバリに適応していない。
システムテーブルスペースをなくしたにかかわらず、SEGMENT HEADERを格納したフィルタもなくした場合に適応している。
簡単にいうと、シーン2の方法でTRUNCATEされたデータをリカバリできないに限って、それ以外の場合はScan Tables From Segmentsを使ってください。Scan Tables From Segmentsを使っても、必要とするデータも見つからないときにScan Tables From Extentsを使うことに考えてください。
私たちはScan Tables From Segmentsモードを優先的に利用することを勧めている。
Scan Tables From Segments完成したら、インタフェース左側の樹形図を起動できる。
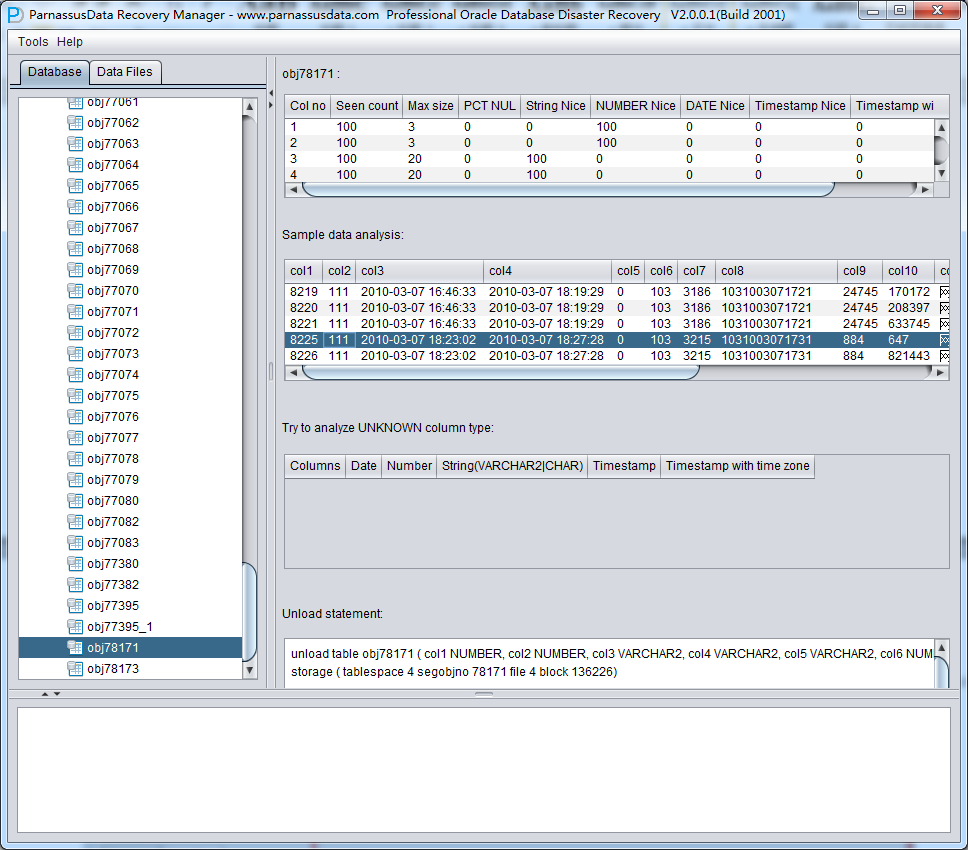
Scan Tables操作はSEG$の中のSEGMENT HEADER情報でデータテーブルの情報を構造する、樹形図の中に一つのノードが一つのデータテーブルセグメントを意味する。、その名はobj+データセグメントが記録したDATA OBJECT ID。
一つのノードをクリックして、インタフェース右側のコラムを見てください。
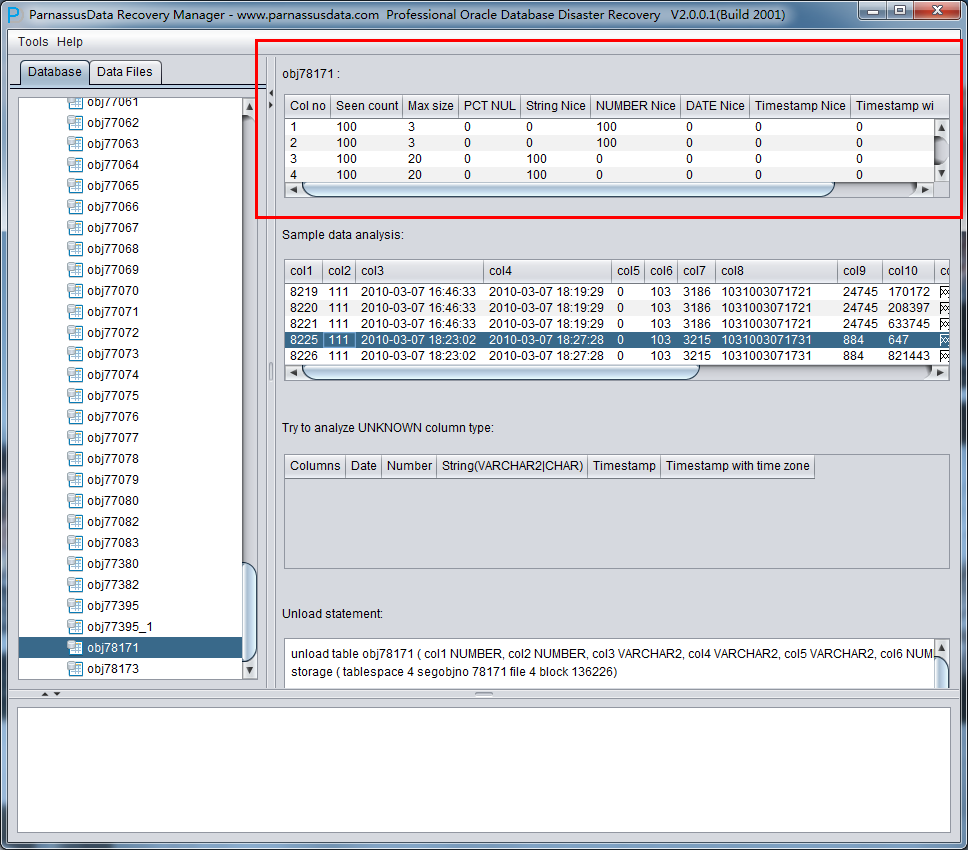
インテリジェントフィールドタイプ分析
システムスペースをなくしたゆえに、NO-Dictionaryモードではデータテーブルの構造情報がない。その構造情報にはテーブルのフィールド 名とフィールドタイプを含んでいて、そしてOracleでこれらの情報がディクショナリー情報として格納する。ユーザーがテーブルスペースを使うときに、 データセグメントのROW行データで一つ一つのフィールドのタイプを当てる必要がある。PRMは最先端のJava予測技術を応用し、10種以上のメイン データ・タイプも含まれている。
インテリジェント分析の正確度が90%を超え、自動的に多くのシーンを解決できる。
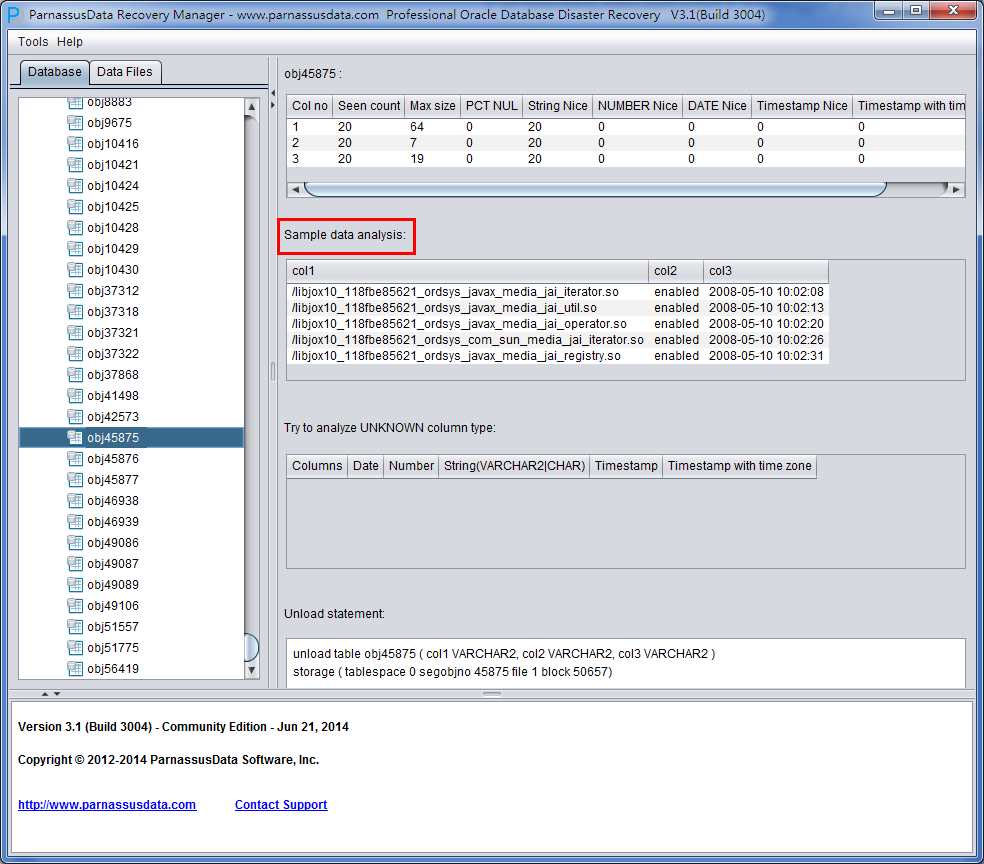
右側のコラムのフィールドの意味:
- Col1 noフィールド番号
- Seen Count: 獲得した行数
- MAX SIZE:最大の長さ、単位はバイト
- PCT NULL: 獲得したNULLの比率
- String Nice: そのフィールドを文字列に解析し、そして成功した例
- Number Nice:そのフィールドを数字に解析し、そして成功した例
- Date Nice: そのフィールドをDateに解析し、そして成功した例
- Timestamp Nice: そのフィールドをTimestampに解析し、そして成功した例
- Timestamp with timezone Nice: そのフィールドをTimestamp with timezone Niceに解析し、そして成功した例
サンプルデータ分析Sample Data Analysis
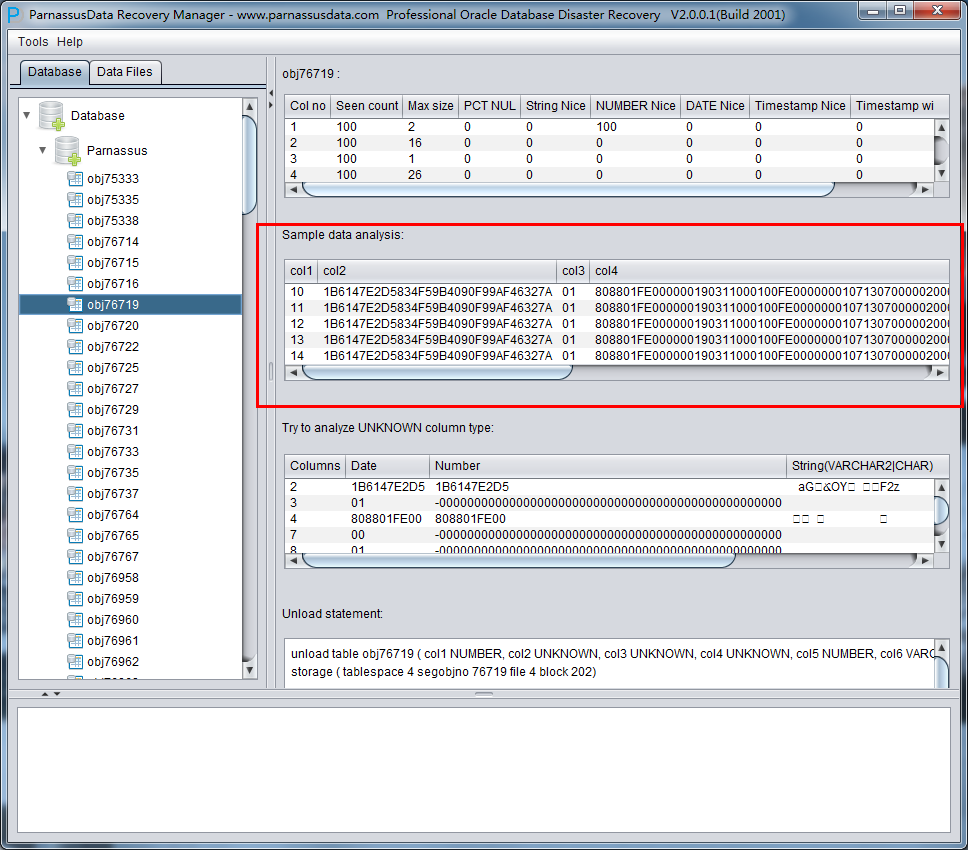
この部分にはインテリジェントフィールドタイプ解析の結果で10個のデータを解析し、そしてその結果を示す。例のデータによって、ユーザーがそのデータセグメントの中のデータを格納する様子を、もっと詳しく理解できる。
もしデータセグメントにあるデータは10個を足りていないなら、すべての記録が表示される。
TRY TO ANALYZE UNKNOWN column type:
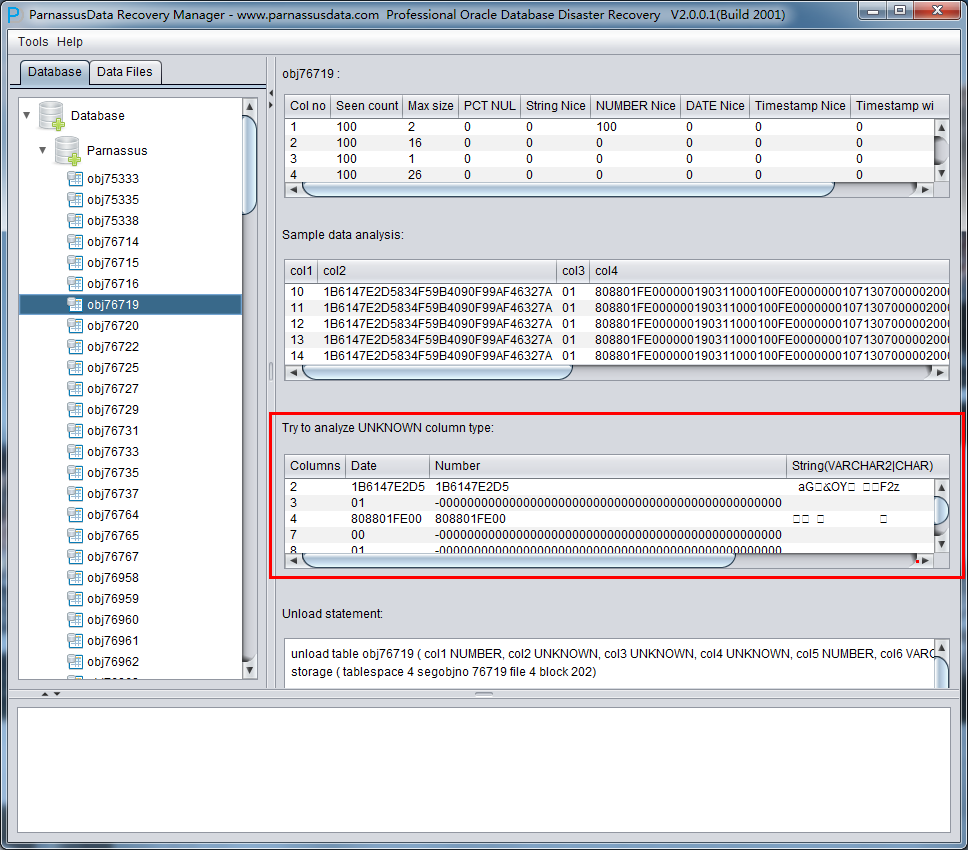
この部分はインテリジェントフィールド型解析が100%で確認できないフィールドをいろんな手段をつかって解析して、ユーザーは自身の判断でタイプを判明できる。
PRM今まだ支持していないタイプは:
XDB.XDB$RAW_LIST_T、XMLTYPE、カスタムタイプなど。
Unload Statement:
この部分はPRMが生成したUNLOAD文で、システムが内部的に使用する場合とPRM開発チーム及び ParnassusDataエンジニアがサポートしている場合にしか使えない。
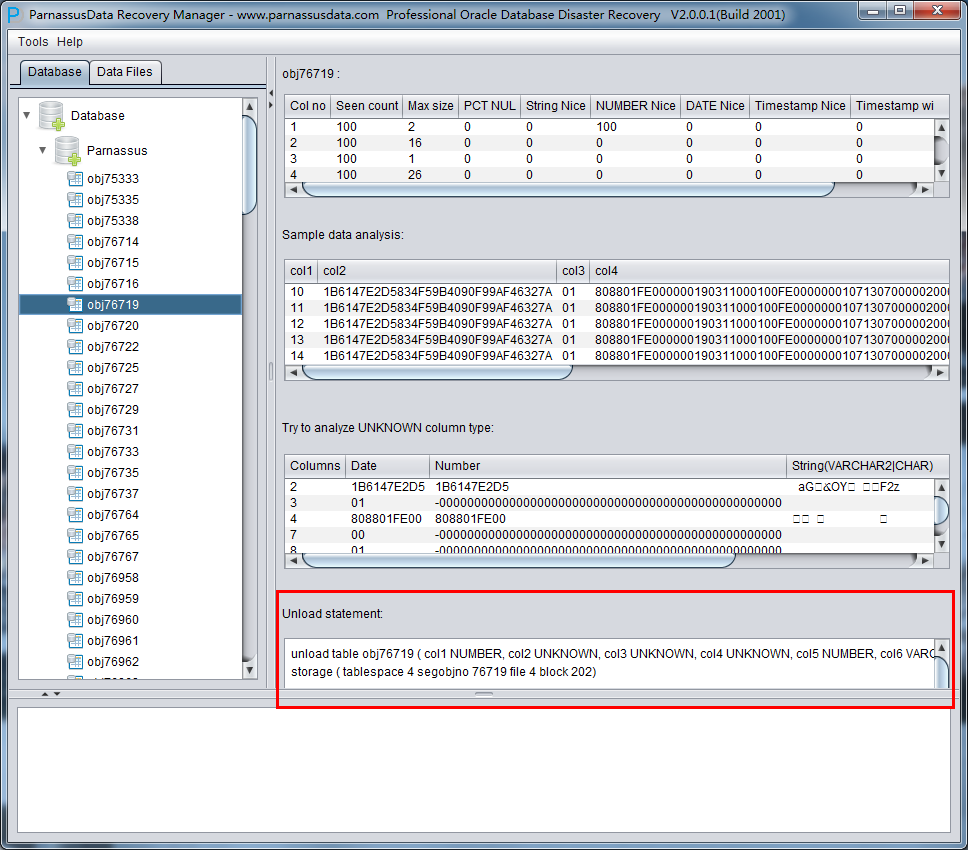
ドも使える。ディクショナリーモードと比べれば、主な違いは非ディクショナリーモードでユーザーが自身でフィールドのタイプを実行できる、以下のよ うに、一部のフィールドタイプはUNKNOWNで、これらのフィールドはPRMがまだ支持していないフィールドで、あるいはPRMのインテリジェント解析 が順調に解析できなかったから。
もしユーザーがこのテーブルが設計するときの構造さえ知っていれば(アプリ開發者からのフィルタもいい)、自身で正確なColumn Typeを選べるようになる。これによって、PRMがそのテーブルのデータを順調に目標データベースにデータバイパスできる。
誤操作でテーブルスペースと一部のアプリテーブルスペースデータフィルタを削除した。
D社のSAは誤操作で、オンライン業務データベースのSYSTEMテーブルスペースのフィルタと一部のアプリテーブルスペースフィルタを削除した。
このシーンで、一部のアプリデータスペースフィルタが削除されたから、その中にデータテーブルのSEGMENT HEADERフィルタを含む可能性があるので、Scan Tables From Segment Headerより、Scan Tables From Extentsを使うほうがいい。
ステップは以下の通り:
- Recovery Wizardに入って、No-Dictionaryモードを選んで、すべて使用可能なデータフィルタを追加し、Scan Databaseを実行する。
2.データベースを選んで、マウスの右ボタンでScan Tables From Extentsをクリックする
3.PRMインタフェースに生成した対象樹形図のデータを分析して、導出あるいはデータバイパスする。
4.そのほかの操作はシーン4と同じ。
リカバリシーン6 壊されたASM Diskgroupからデータベースのデータを抽出する
D社はASM方法でフィルタシステムとRAWデバイスをかわったが、いま運用しているのは11.2.0.1バーションで、bugが多いので、ASM DISKGROUPディスくがMOUNTをロードできなくて、いろんな手を打ったが、なかなか効果が出ない。
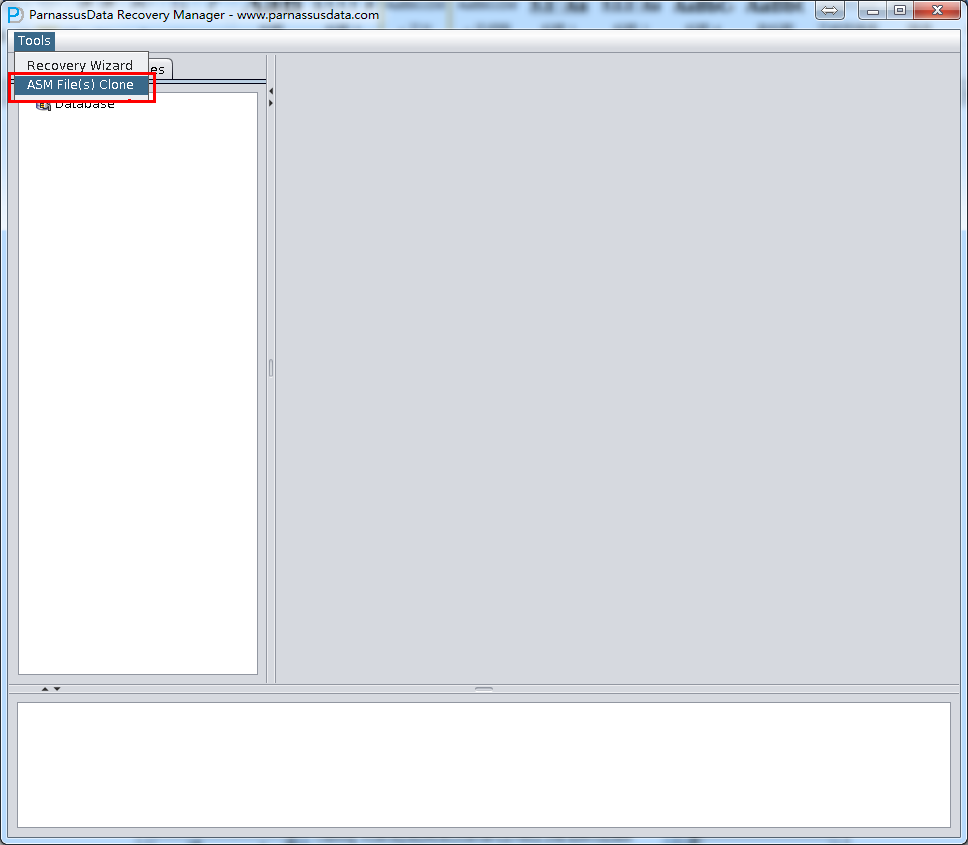
このシーンで使えるのはPRMのASM Files Cloneフィルタコーピー機能です。この機能はダンメージを受けたASM Diskgroupからデータベースフィルタをコーピーできる。
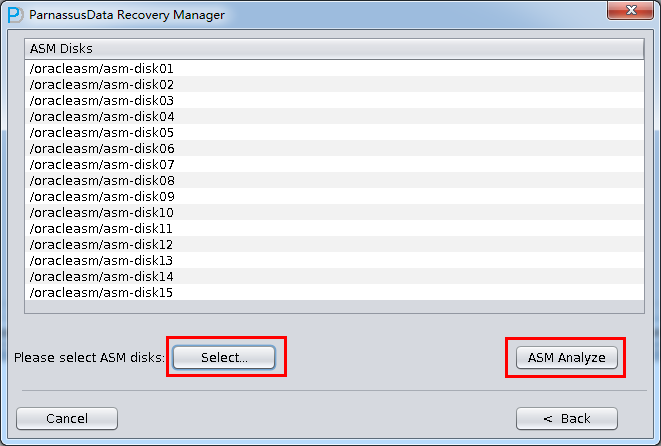
1.インタフェースをオープンして、ToolsメニューコラムでASM File(s) Cloneを選んでください。:
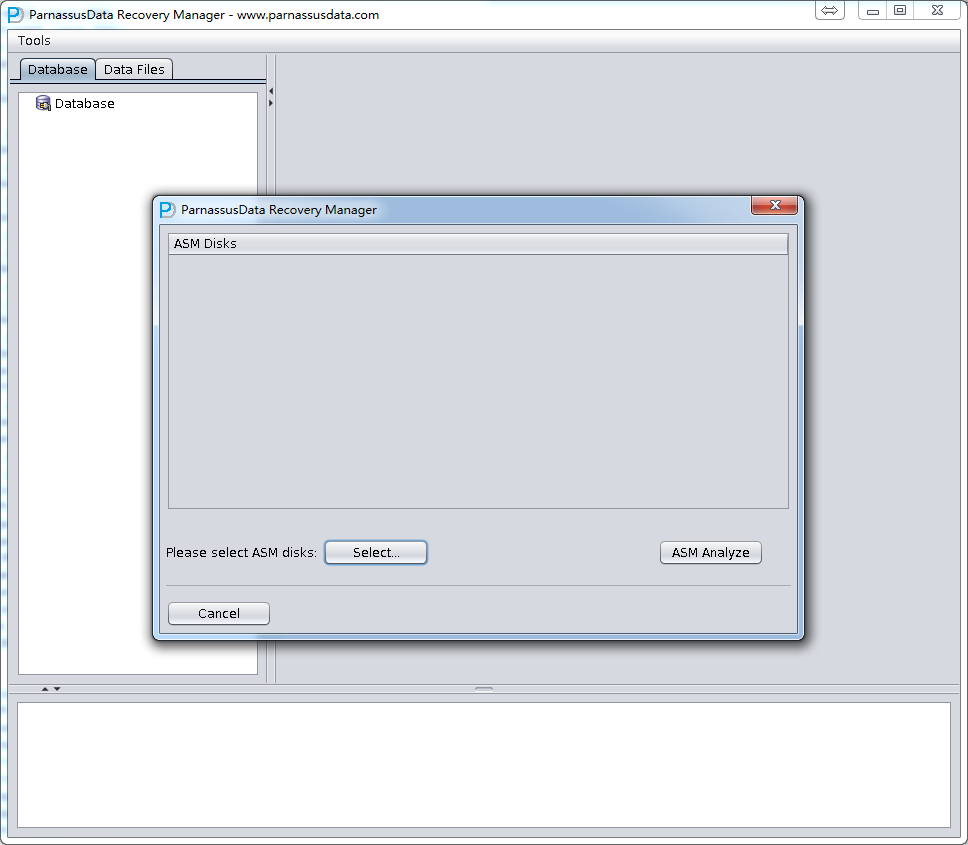
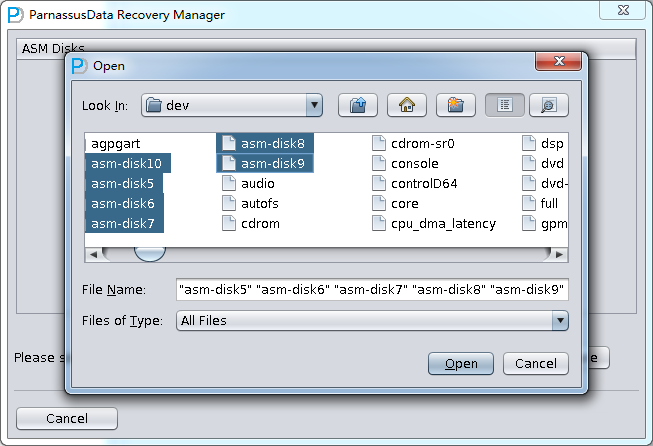
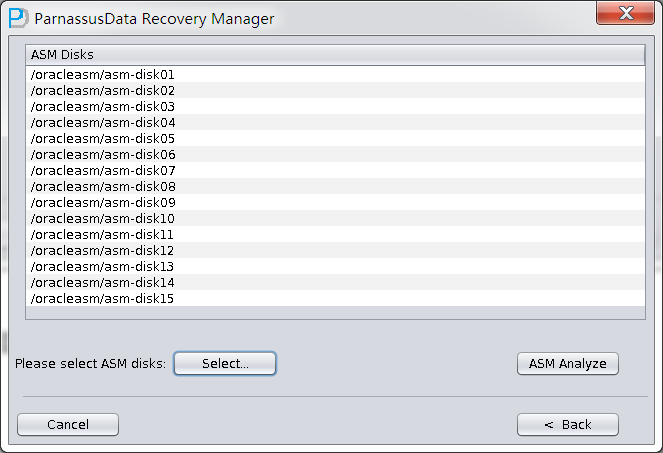
- ASM Disksに入って、SELECT…をクリックして、使用可能なASM Disksを追加する。例えば、/dev/asm-disk5(linux)。すべての使用可能なLUNを追加した後、ASM analyzeボタンをクリックしてください。
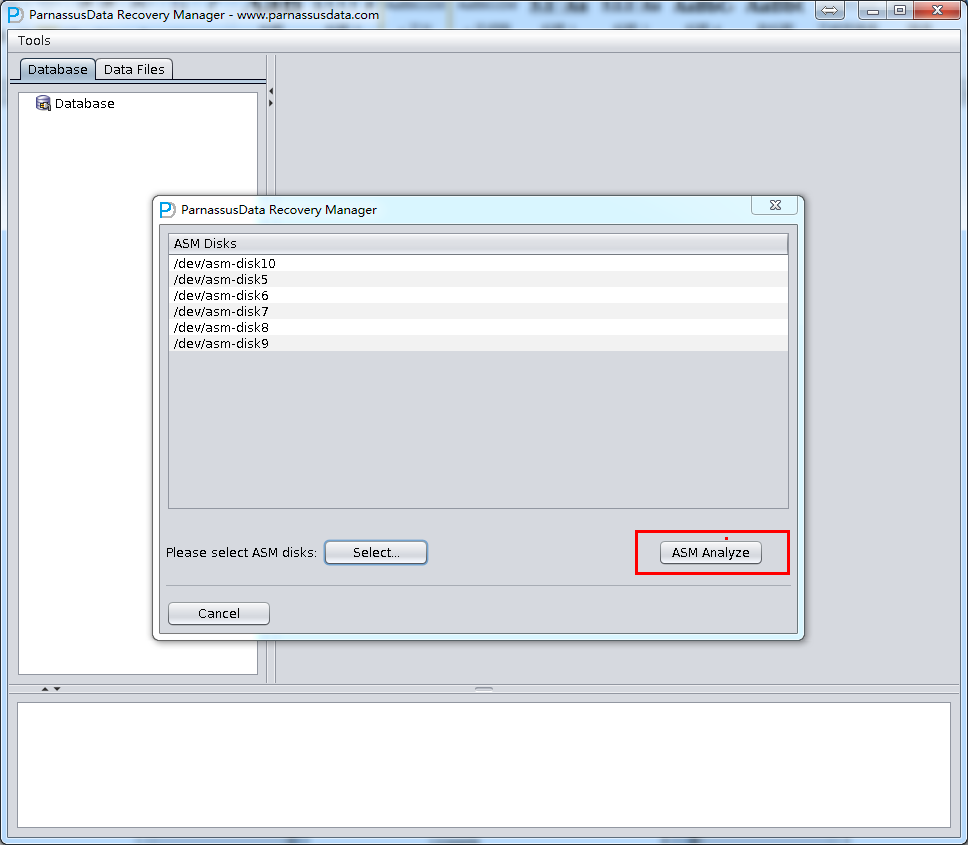
ASM analyzeがDisk groupの中のフィルタとアドレス(File Extent Map)を見つけ出すために、指定されたASM Diskのディスクヘッダーを分析する。これらのデータは以後も使えるように、Derbyデータベースに記録される。ここで、PRMはASMあらゆるの Metadataを収集して分析して格納する。そして、いろいろな方法でPRMの基本的な機能を改善し、グラフの形式でユーザーに示す。
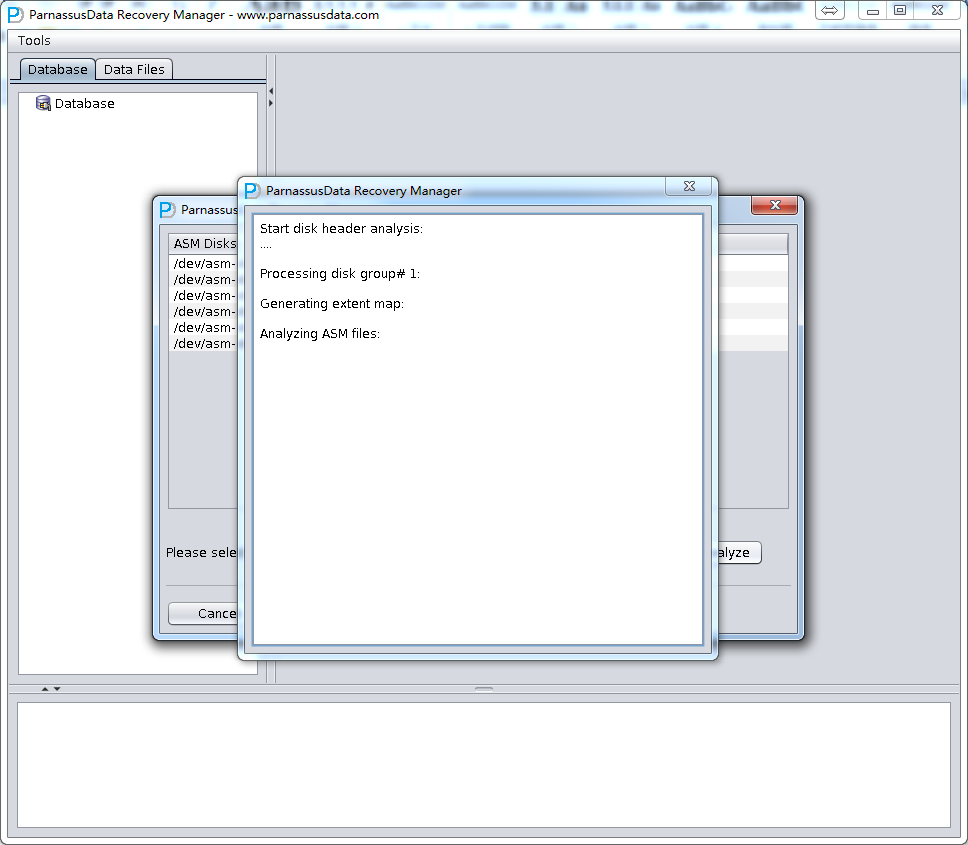
ASM Analyzeが完成したら、PRMは探し出したASMのフィルタをリストにする。どれをコーピーする必要があるか、ユーザーが自分で決めて、コーピー先を指定することもできる。
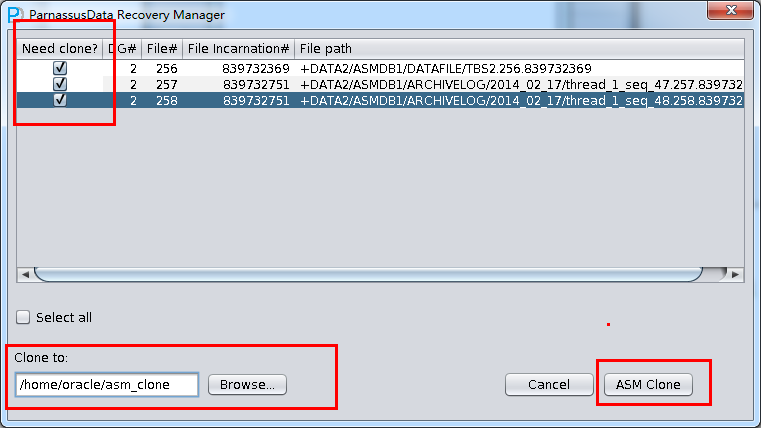
コーピー段階で、ASM Fileのコーピー進捗状況を示されて、完成したら、OKをクリックしてください。
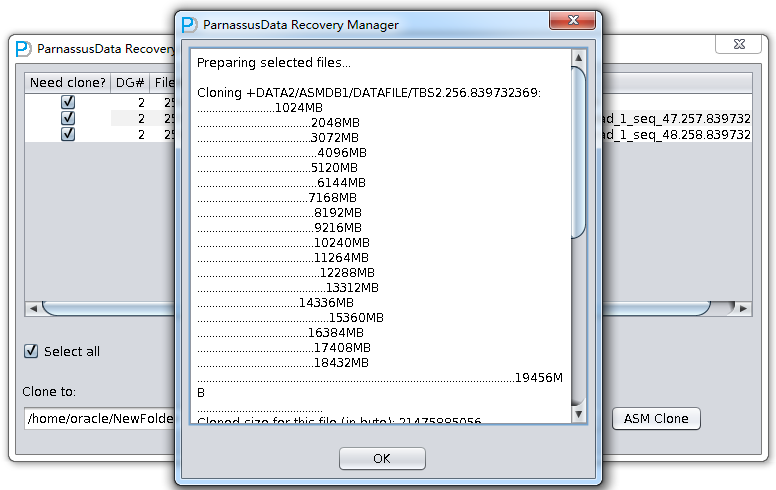
コーピー段階の進捗状況は以下のようにエクスポートする。
|
Preparing selected files…
Cloning +DATA2/ASMDB1/DATAFILE/TBS2.256.839732369: ……………………..1024MB ………………………………..2048MB ………………………………..3072MB ………………………………….4096MB ………………………………..5120MB ………………………………….6144MB ……………………………….7168MB …………………………………8192MB …………………………………9216MB …………………………………10240MB …………………………………11264MB …………………………………..12288MB …………………………………….13312MB …………………………….14336MB ……………………………………..15360MB ……………………………….16384MB …………………………………17408MB …………………………………18432MB …………………………………………………………………………………………….19456MB …………………………………… Cloned size for this file (in byte): 21475885056
Cloned successfully!
Cloning +DATA2/ASMDB1/ARCHIVELOG/2014_02_17/thread_1_seq_47.257.839732751: …… Cloned size for this file (in byte): 29360128
Cloned successfully!
Cloning +DATA2/ASMDB1/ARCHIVELOG/2014_02_17/thread_1_seq_48.258.839732751: …… Cloned size for this file (in byte): 1048576
Cloned successfully!
All selected files were cloned done. |
Dbvあるいはrman validateコマンドによって、コーピーされたフィルタを確認できる。例えば:
|
rman target /
RMAN> catalog datafilecopy ‘/home/oracle/asm_clone/TBS2.256.839732369.dbf';
cataloged datafile copy datafile copy file name=/home/oracle/asm_clone/TBS2.256.839732369.dbf RECID=2 STAMP=839750901
RMAN> validate datafilecopy ‘/home/oracle/asm_clone/TBS2.256.839732369.dbf';
Starting validate at 17-FEB-14 using channel ORA_DISK_1 channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: including datafile copy of datafile 00016 in backup set input file name=/home/oracle/asm_clone/TBS2.256.839732369.dbf channel ORA_DISK_1: validation complete, elapsed time: 00:03:35 List of Datafile Copies ======================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN —- —— ————– ———— ————— ———- 16 OK 0 2621313 2621440 1945051 File Name: /home/oracle/asm_clone/TBS2.256.839732369.dbf Block Type Blocks Failing Blocks Processed ———- ————– —————- Data 0 0 Index 0 0 Other 0 127
Finished validate at 17-FEB-14
|
では’、 ASMLIBを使っているASM環境はどうやってPRMを使うでしょう。
簡単に言うと、asmlibについてのASM DISKはOSでll /dev/oracleasm/disksの形式で保存する、例えば:/dev/oracleasm/disksでのフィルタをPRM ASM DISKに追加してすればいい。
|
$ll /dev/oracleasm/disks
total 0 brw-rw—- 1 oracle dba 8, 97 Apr 28 15:20 VOL001 brw-rw—- 1 oracle dba 8, 81 Apr 28 15:20 VOL002 brw-rw—- 1 oracle dba 8, 65 Apr 28 15:20 VOL003 brw-rw—- 1 oracle dba 8, 49 Apr 28 15:20 VOL004 brw-rw—- 1 oracle dba 8, 33 Apr 28 15:20 VOL005 brw-rw—- 1 oracle dba 8, 17 Apr 28 15:20 VOL006 brw-rw—- 1 oracle dba 8, 129 Apr 28 15:20 VOL007 brw-rw—- 1 oracle dba 8, 113 Apr 28 15:20 VOL008 |
/dev/oracleasm/disksでのフィルタをPRM ASM DISKに追加してください
リカバリシーン7 ASMの環境でデータベースが起動できない
D社の一番大事なCRMリポジトリがASM Diskgroupに追加したディスクがI/O問題があるから。SYSTEMテーブルスペースのDBFデータフィルタがエラになり、データベースが正常に起動できない。
この時はPRMを通って、ASM DiskgroupからDATAFILEを全部フィルタシステムにコーピーして、リカバリシーン6のように、データベースを修復する。
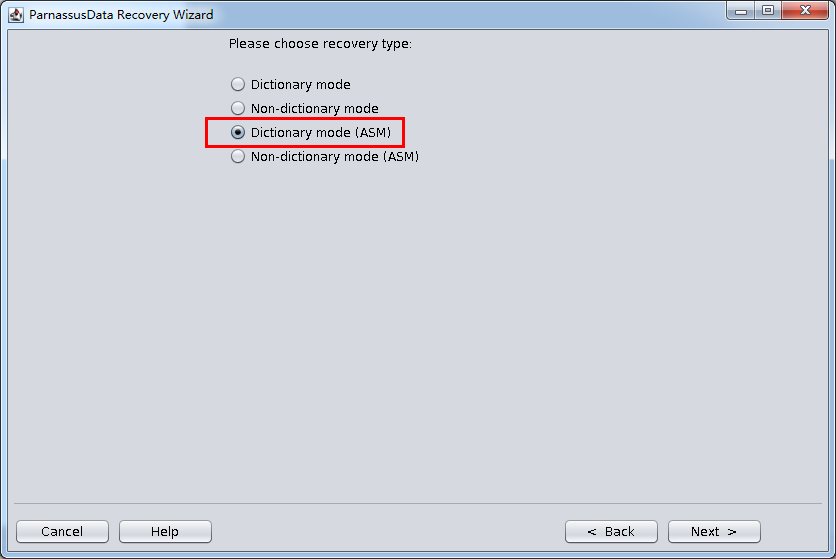
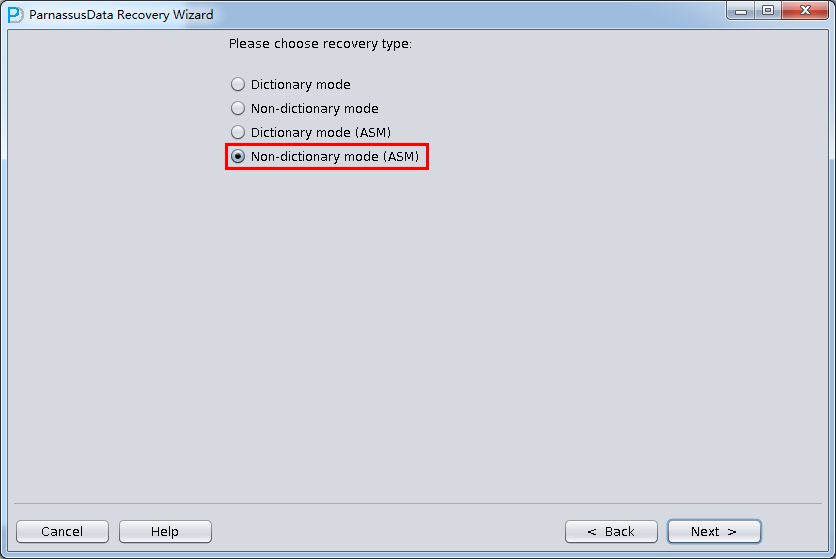
PRMのDictionary Mode(ASM)もASMのディクショナリーモードで問題を解決できる。簡単な流れは以下の通り:
- Recovery Wizard
- Dictionary Mode(ASM)
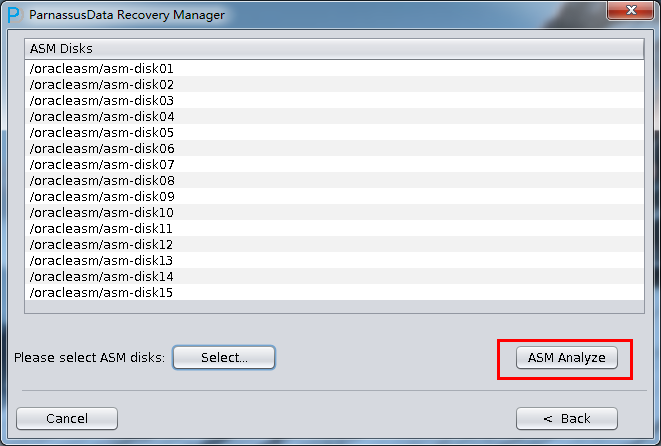
- 必要なASM DISKを追加し(リカバリしたいデータベースを含むASM Disk GroupにすべてのASM DISK)
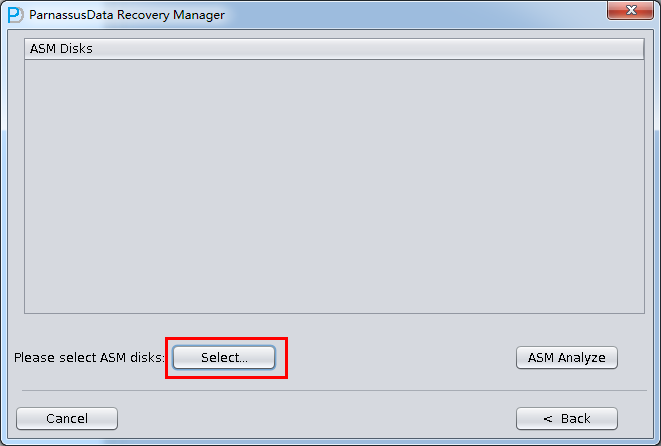
- ASM analyze クリックする
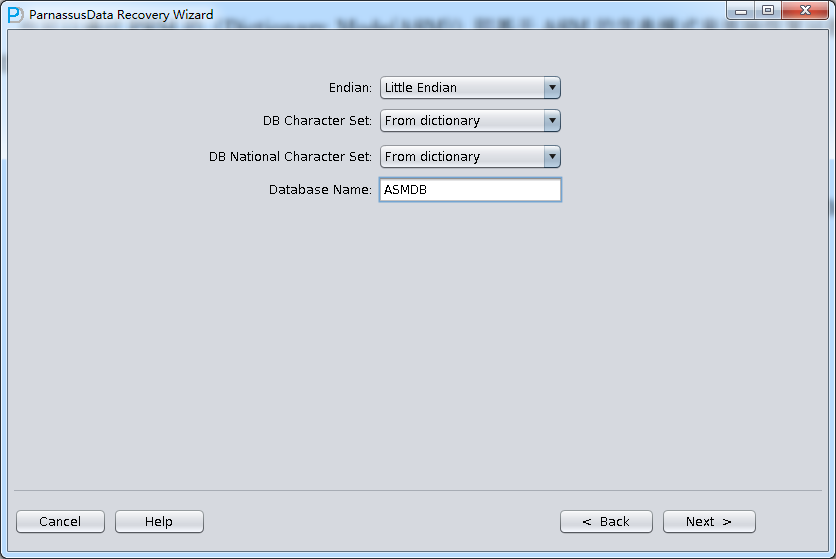
- あとのフィルタのために、ふさわしいEndianを選ぶ。
- ASM analzeのフィルタリストで必要とするデータフィルタを選んでください。一つのリポジトリしかない場合に、Select allを選んでください。
- ロードをクリックして、後のリカバリはシーン3に似ている。
リカバリシーン8 ASMでSYSTEMテーブルスペースのリカバリを削除した(なくした)
D社の技術者は誤操作で一番大事なデータベースのSYSTEMテーブルスペースFILE#=1のフィルタと一部のアプリテーブルスペースを削除したことによって、データベースが順調に起動できない。
このシーンでPRMの《Non-Dictionary Mode(ASM) 》ASMの非ディクショナリーモードによって、今のデータフィルタに基づき、いちはやくデータをリカバリできる。
簡単な流れは以下の通り:
- Recovery Wizard
- Dictionary Mode(ASM)
- 必要なASM DISKを追加し(リカバリしたいデータベースを含むASM Disk GroupにすべてのASM DISK)
- ASM analyze クリックする
- あとのフィルタのために、ふさわしいEndianを選ぶ。(非ディクショナリーモードなので、人工で選ぶ必要がある)。
- ASM analzeのフィルタリストで必要とするデータフィルタを選んでください。一つのリポジトリしかない場合に、Select allを選んでください。
- ロードをクリックして、後のリカバリはシーン3に似ている。
リカバリシーン9 誤操作でDROP TABLESPACEしたデータをリカバリする
D社の職員があるいらないテーブルスペースを削除したいだが、つまりDROP TABLESPACE INCLUDING CONTENTS操作で、DROP TABLESPACEを実行したら、開發者がDROPされたTABLESPACEにSCHEMAという重要なデータがあるが、テーブルスペースがDROP されて、バックアップもないので、まさに万策尽きという状態である。
こういう時にやくに立てるのはPRMのNo-Dictモードで、DROP TABLESPACEされたすべてのフィルタを抽出してください。多くのデータがこの方法でリカバリできると思うが、非ディクショナリーモードなので、も う一度リカバリしてきたデータとアプリデータテーブルを対応する必要がある。この時に、アプリ開發者の協力が必要で、データはどこのテーブルに属している のか人工的に判明する必要がある。DROP TABLESPACE操作がデータディクショナリーを変更した上で、OBJ$で該当するテーブルスペースの目標を削除したから、OBJ$から DATA_OBJECT_IDとOBJECT_NAMEの間の関係を得られない。この時に、以下の方法を活かし、DATA_OBJECT_IDと OBJECT_NAMEの関係をより多く手に入ることができる。
|
select tablespace_name,segment_type,count(*) from dba_segments where owner=’PARNASSUSDATA’ group by tablespace_name,segment_type;
TABLESPACE SEGMENT_TYPE COUNT(*) ———- ————— ———- USERS TABLE 126 USERS INDEX 136
SQL> select count(*) from obj$;
COUNT(*) ———- 75698
SQL> select current_scn, systimestamp from v$database;
CURRENT_SCN ———– SYSTIMESTAMP ————————————————————————— 1895940 25-4月 -14 09.18.00.628000 下午 +08:00
SQL> select file_name from dba_data_files where tablespace_name=’USERS';
FILE_NAME ——————————————————————————– H:\PP\MACLEAN\ORADATA\PARNASSUS\DATAFILE\O1_MF_USERS_9MNBMJYJ_.DBF
SQL> drop tablespace users including contents;
テーブルスペースもう削除した
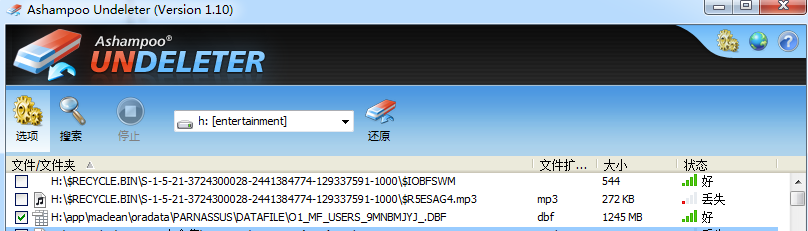
C:\Users\maclean>dir H:\APP\MACLEAN\ORADATA\PARNASSUS\DATAFILE\O1_MF_USERS_9MNBMJYJ_.DBF
ドライブの巻はentertainment 巻のシリアルナンバーはentertainment
フィルタが見つからない
drop tablespaceした後、TABLESPACEに該当するフィルタがOSで削除されたから。
|
この時に、フィルタリカバリツールでリカバリできる。
PRMを起動する=> recovery Wizard =>非ディクショナリーモード
非ディクショナリーモードなので、自分からふさわしい文字セットを選ぶ必要がある。
先リカバリしてきたフィルタをクリックしてスキャンする。
そしてセグメントヘッダあるいはディスク領域スキャンテーブルを選んでください。セグメントヘッダーがすべてのテーブルをひとつも漏れずに探し出すことができない場合に、ディスク領域でもう一度スキャンしてください。
そして、インタフェースの樹形図にものすごく大量なOBJXXXXXのようなテーブルが現れる。ここのOBJXXXXXはテーブルの DATA_OBJECT_IDであって、そのシステムの開發応用モードに詳しい技術者がサンプルデータ分析を参照して、テーブルとアプリテーブルをつなが る。
もし、協力する技術者がいないなら、以下の方法を考えてください。
この例で使っているのはDROPしたTABLESPACEテーブルのスペースであって、データベース自身はなんの問題もないので、FLASHBACK QUERYを活かし、DATA_OBJECT_IDとテーブル名前のつながりを獲得できる。
|
SQL> select count(*) from sys.obj$;
COUNT(*) ———- 75436
SQL> select count(*) from sys.obj$ as of scn 1895940; select count(*) from sys.obj$ as of scn 1895940 * 第一行がエラになり
ORA-01555:スナップショットが古すぎて、ロールバックセグメント番号(名は”SYSTEM”)が小さすぎる。
初めてはFLASHBACK QUERYでOBJ$の記録を見つけ出したいが、SYSTEM ROLLBACK SEGMENTを使ったことによって、ORA-01555になる。
この時にAWRビューDBA_HIST_SQL_PLANを使ってください。七天以内でそのテーブルにアクセスしたら実行計画からOBJECT#とOBJECT_NAMEのつながりが得られる。
SQL> desc DBA_HIST_SQL_PLAN 名称 是否为空? 类型 名前 ブランクかいなか タイプ —————————————– ——– ———————– DBID NOT NULL NUMBER SQL_ID NOT NULL VARCHAR2(13) PLAN_HASH_VALUE NOT NULL NUMBER ID NOT NULL NUMBER OPERATION VARCHAR2(30) OPTIONS VARCHAR2(30) OBJECT_NODE VARCHAR2(128) OBJECT# NUMBER OBJECT_OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(31) OBJECT_ALIAS VARCHAR2(65) OBJECT_TYPE VARCHAR2(20) OPTIMIZER VARCHAR2(20) PARENT_ID NUMBER DEPTH NUMBER POSITION NUMBER SEARCH_COLUMNS NUMBER COST NUMBER CARDINALITY NUMBER BYTES NUMBER OTHER_TAG VARCHAR2(35) PARTITION_START VARCHAR2(64) PARTITION_STOP VARCHAR2(64) PARTITION_ID NUMBER OTHER VARCHAR2(4000) DISTRIBUTION VARCHAR2(20) CPU_COST NUMBER IO_COST NUMBER TEMP_SPACE NUMBER ACCESS_PREDICATES VARCHAR2(4000) FILTER_PREDICATES VARCHAR2(4000) PROJECTION VARCHAR2(4000) TIME NUMBER QBLOCK_NAME VARCHAR2(31) REMARKS VARCHAR2(4000) TIMESTAMP DATE OTHER_XML CLOB
例えば select object_owner,object_name,object# from DBA_HIST_SQL_PLAN where sql_id=’avwjc02vb10j4′
OBJECT_OWNER OBJECT_NAME OBJECT# ——————– —————————————- ———-
PARNASSUSDATA TORDERDETAIL_HIS 78688
Select * from (select object_name,object# from DBA_HIST_SQL_PLAN UNION select object_name,object# from GV$SQL_PLAN) V1 where V1.OBJECT# IS NOT NULL minus select name,obj# from sys.obj$;
select obj#,dataobj#, object_name from WRH$_SEG_STAT_OBJ where object_name not in (select name from sys.obJ$) order by object_name desc;
もう一つの例 SELECT tab1.SQL_ID, current_obj#, tab2.sql_text FROM DBA_HIST_ACTIVE_SESS_HISTORY tab1, dba_hist_sqltext tab2 WHERE tab1.current_obj# NOT IN (SELECT obj# FROM sys.obj$ ) AND current_obj#!=-1 AND tab1.sql_id =tab2.sql_id(+);
|
以上はユーザーがどうしてもリカバリしたいデータテーブルについて、なんの情報も得られない場合にしか使えない。(つまり、このアプリモードについてのひともスクリプトもテキストもない場合)、それにAWRデータに頼っていて、正確性には少し問題がある。
リカバリシーン10 誤操作でDROPしたテーブルのリカバリ
D社のアプリ開發者がASMの環境で、なんのバックアップもないのに、システムの肝心なアプリテーブルをDROPした。そのときに、PRMですぐに 大部分のデータをリカバリできる。10gのあと、recyclebinゴミ箱を追加した。まずはDBA_RECYCLEBINSビューを確認して、 DROPしたテーブルがそこにあるか否かをたしかめる。もしそこにもなかったら、PRMでリカバリしてください。
リカバリの流れは以下の通り:
まずはDROPされたデータテーブルを含むテーブルスペースを見つけ出す。
ディクショナリーをけんさくして、あるいはLOGMINERでDROPされたデータテーブルのDATA_OBJECT_IDを見つけ出す。 DATA_OBJECT_IDを得られない場合にはNON-DICTモードでPRMを起動する。DROPされたデータテーブルを含むテーブルスペースにす べてのフィルタを追加したら、SCAN DATABASE+SCAN TABLE from Extent MAP。
DATA_OBJECT_IDによって、データテーブルを見つけて、DataBridgeモードでもとのデータベースに伝送する。
|
SQL> select count(*) from “MACLEAN”.”TORDERDETAIL_HIS”;
COUNT(*) ———- 984359
SQL> SQL> create table maclean.TORDERDETAIL_HIS1 as select * from maclean.TORDERDETAIL_HIS;
Table created.
SQL> drop table maclean.TORDERDETAIL_HIS;
Table dropped. |
Logminerに通って、あるいはリカバリシーン9の方法で大抵なDATA_OBJECT_IDを得られる、LOGMINERを利用するスクリプトは以下の通り:
|
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => ‘/oracle/logs/log1.f’, OPTIONS => DBMS_LOGMNR.NEW);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => ‘/oracle/logs/log2.f’, OPTIONS => DBMS_LOGMNR.ADDFILE);
Execute DBMS_LOGMNR.START_LOGMNR(DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG+DBMS_LOGMNR.COMMITTED_DATA_ONLY);
SELECT * FROM V$LOGMNR_CONTENTS ;
EXECUTE DBMS_LOGMNR.END_LOGMNR; |
たとえここでDATA_OBJECT_ID得られなくとも、データテーブルが多くない場合に人工的にリカバリしたいデータテーブルを見つけ出すことができる。
まずはDROPされたデータテーブルを含むテーブルスペースをOFFLINEする。
|
SQL> select tablespace_name from dba_segments where segment_name=’TPAYMENT';
TABLESPACE_NAME —————————— USERS
SQL> select file_name from dba_data_files where tablespace_name=’USERS';
FILE_NAME —————————————————————- +DATA1/parnassus/datafile/users.263.843694795
SQL> alter tablespace users offline;
Tablespace altered. |
PRMを起動して、NON-DICTモードに入って、該当するデータフィルタを追加し、SCAN DATABASE+SCAN TABLE From Extentsを選んでください。
ASM DiskgroupにあるすべてのASM Disks追加したら、ASM analyzeをクリックしてください。
非ディクショナリーモードなので、必要な文字セットを入力してください。
DROPされたデータテーブルを含むテーブルフィルタをクリックすればいい、ほかのフィルタはどうでもいい。そしてSCANをクリックする。
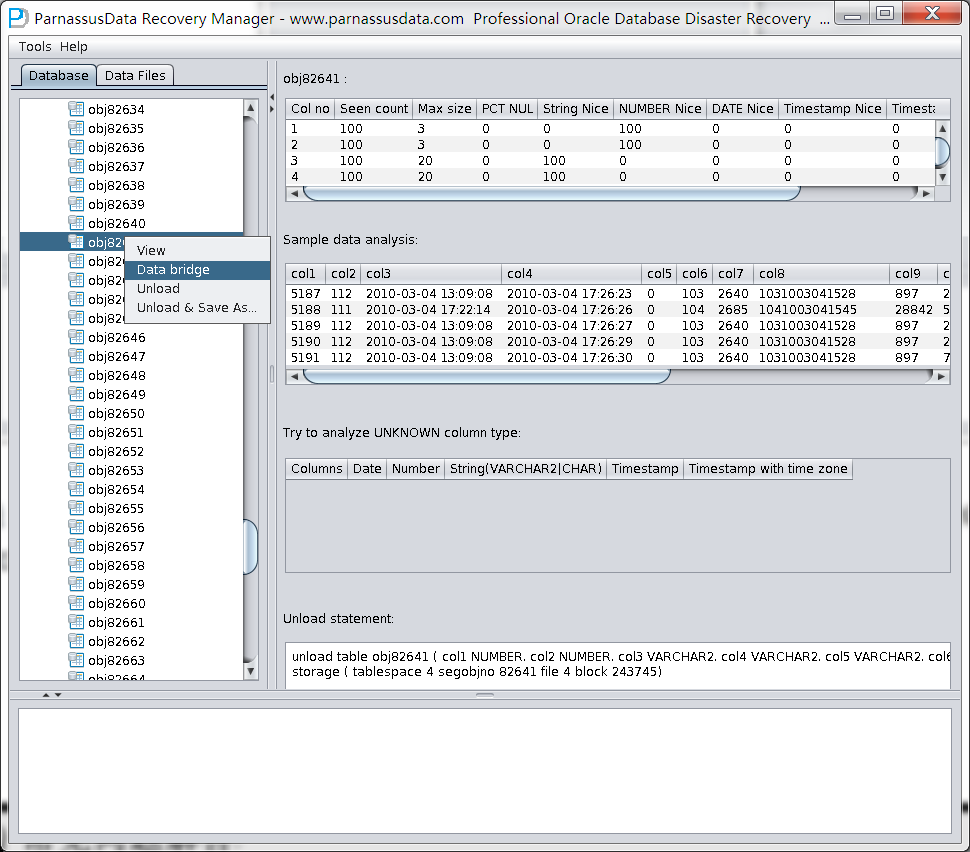
生成したデータベースの名前をクリックし、右ボタンでscan tables from extentsを選んでください。
人工的にDATA_OBJECT_ID=82641のデータはDROPされたTORDERDETAIL_HISテーブルに該当し、DataBridge技術でモートのリポジトリに伝送する。
FAQ よくある質問
データベースの文字セットが分からなかったらどうすればいい?
Oracleアラームロゴalert.logを確認することによって、データベースの文字セットが確認できる。例えば:
|
[oracle@mlab2 trace]$ grep -i character alert_Parnassus.log
Database Characterset is US7ASCII Database Characterset is US7ASCII alter database character set INTERNAL_CONVERT AL32UTF8 Updating character set in controlfile to AL32UTF8 Synchronizing connection with database character set information Refreshing type attributes with new character set information Completed: alter database character set INTERNAL_CONVERT AL32UTF8 alter database national character set INTERNAL_CONVERT UTF8 Completed: alter database national character set INTERNAL_CONVERT UTF8 Database Characterset is AL32UTF8 Database Characterset is AL32UTF8 Database Characterset is AL32UTF8 |
なぜPRMいつもシャットダウンするあるいはgc warning: うおeated allocation of very large block (appr.size 512000)”などのエラになるでしょう?
それは恐らく推薦していないJAVA環境を使ったせいと思う。とくに、Linuxプラッドフォームでredhat gcj javaを運用したら、よくこのようになる。ParnassusDataはJDK1.6以上の環境でPRMを運用することを勧めてい る。$JAVA_HOME/bin/java –jar prm.jarによって、PRMを起動できる。
JDK 1.6のダウンロードリンクは以下の通り:
PRMのbugを見つけ出したら、どうやってParnassusDataにreport bugすればいいでしょう?
ParnassusDataはあらゆるのreport bugを歓迎する。[email protected]にメールすればいい。メールにbugが出た運用環境、オペレーションシステム、Java運用環境とORACLEデータベースバーション情報を一緒に送信してください。
RPMを起動するときにこのようなエラになったら、どうすればいいでしょう?
Error: no `server’ JVM at `D:\Program Files (x86)\Java\jre1.5.0_22\bin\server\jvm.dll’.
これはユーザーがJAVA Runtime Environment JREをインストールしているが、JDKをインストールしていないからである。PRMの起動スクリプトに-severオプションが追加したから、このオプ ションはJRE 1.5前のバーションにないので、エラになる。
ParnassusDataはJDK1.6以上の環境でPRMを運用することを勧めている。
JDK 1.6のダウンロードリンクは以下の通り
なぜPRMを使うとき、漢字が文字化けになるでしょう?
今我々知っている文字化けに導く原因は以下のふたつがある:
オペレーションシステムに中国語言語パックをインストールしていないので、まともに漢字を映せない。
言語バックをインストールしたが、JAVAの運用環境はJDK 1.4なので、文字化けが出る可能性がある、JDK 1.6以上のバーションを使ってください。
PRMはLOBラージオブジェクトフィールドを支持していないでしょうか?
いまPRMはCLOB、NCLOB、BLOBなどのLOBラージオブジェクトフィールドを支持している。Disable/Enable Storage in ROWなどの場合はLOBへデータバイパスモードも支持している。
LOBラージオブジェクトフィールドには通常のUNLOAD抽出を支持していない。この抽出方法を使ったら、データを導入する場合にものすごくめんどくさいなので、DataBridgeデータバイパスモードを使ってください。
Copyright © 2013, 2019, parnassusdata.com. 版权所有。 dbrecover.com
 沪公网安备 31010802001377号
沪公网安备 31010802001377号