7 x 24 在线支持!
Oracle untruncate using PRM-DUL case study
Case Study on Oracle database recovery via PRM-DUL
CASE 1: Truncate table by mistake
User D had truncated a table by mistake on production environment. The DBA tried to recover table from RMAN backup, and accidently the backup is unavailable. Therefore DBA decided to use PRM-DUL for rescuing all truncated data.
Since all database system files are healthy, DBA just needs to load SYSTEM table data file in dictionary mode and TRUNCATED table file. For example:
|
create table ParnassusData.torderdetail_his1 tablespace users asselect * from parnassusdata.torderdetail_his;
|
Run PRM-DUL, and select Tools =>Recovery Wizard
Click Next
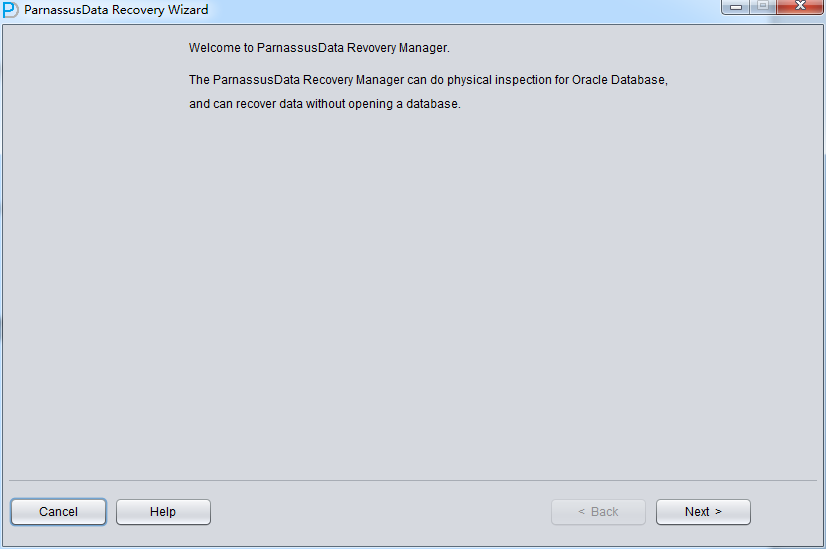
Client did not user ASM storage, therefore just select ‘Dictionary Mode’:
Next, we need to select some characters: including Endian bit order and DBNAME
Since Oracle datafiles have different Endian bit orders on different OS, please choose accordingly:
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
In traditional UNIX, AIX (64-bit), UP-UNIX (64-bit), it use Big Endian bit order,
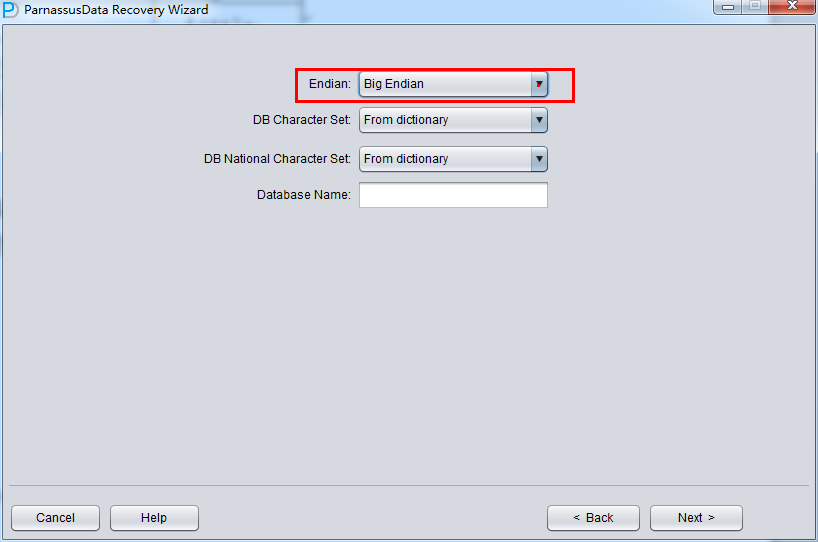
Usually, Linux X86/64, Windows remain default Little Endian:
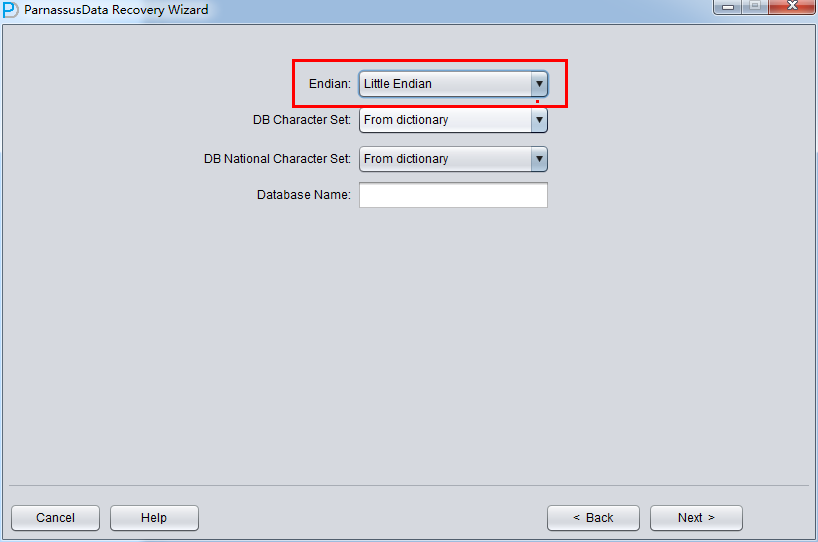
Attention: if your data file was generated on AIX, if you want to recover data on window, please select original Big Endian format.
Since the data file is on Linux X86, we select Little as Endian, and input database name. (The input database name can be different from DB_NAME found in datafile header, the input database name is just an alias. PRM-DUL will check if your PRM-DUL license is valid , the valid license key is generated based on DB_NAME found in datafile header)
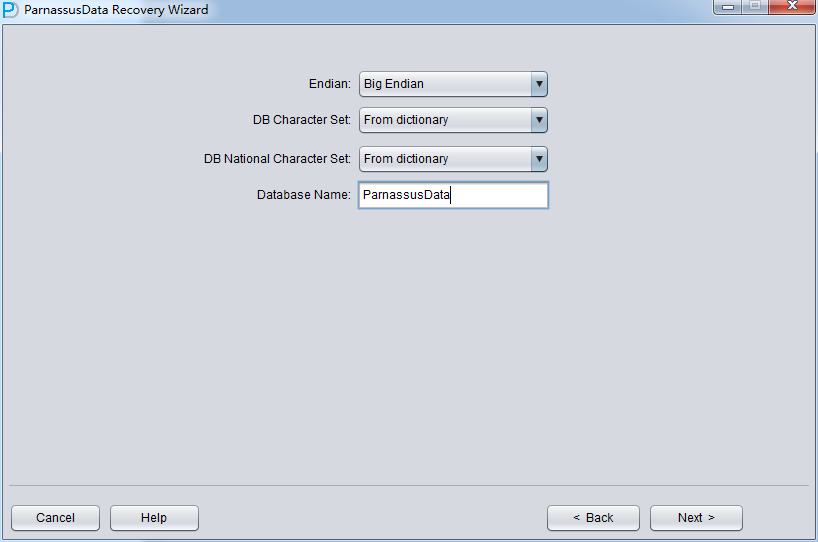
Click Next =>Click Choose Files
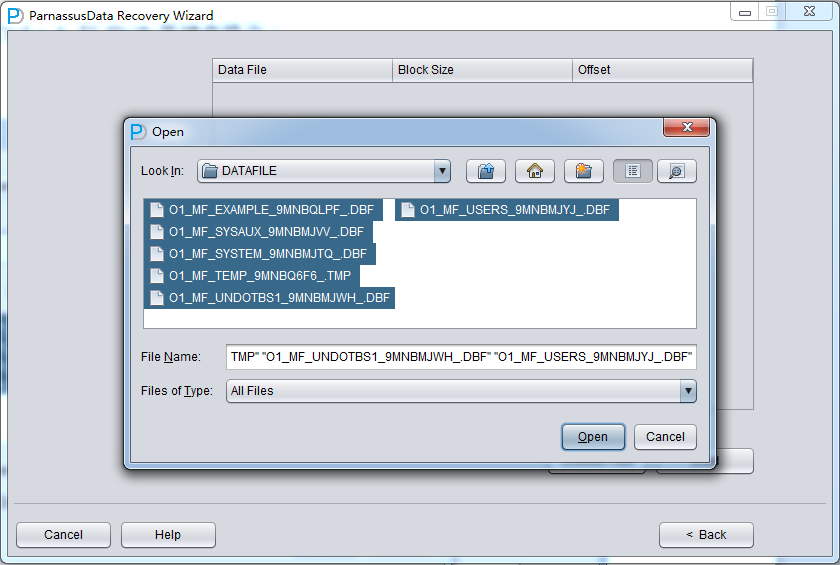
Usually, if the database is not too big, we could select all data files together; if the database capacity is huge and DBA knows the data location, at least you should select both SYSTEM tablespace and specified datafile.
Attention, the GUI Supports Ctrl + A & Shift short keys:
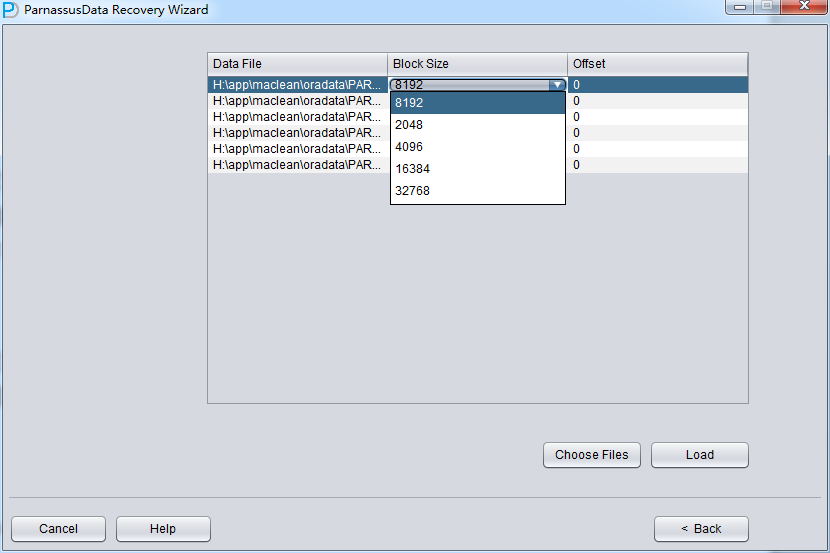
Specify the Block Size (Oracle data block size) according to the real circumstance. For example, if default DB_BLOCK_SIZE is 8K, but part of tablespaces’ block size is 16k,then user has to specify them as correct block size one by one.
OFFSET setting are just for raw device storage mode, for example: on AIX, based on LV of normal VG, the offset will be 4k OFFSET.
If you are using raw device but don’t know what the OFFSET is, please use dbfsize tool which is under $ORACLE_HOME/bin
| $dbfsize /dev/lv_control_01Database file: /dev/lv_control_01Database file type: raw device without 4K starting offsetDatabase file size: 334 16384 byte blocks |
Since all data file block size here is 8K and there is no OFFSET, please click load:
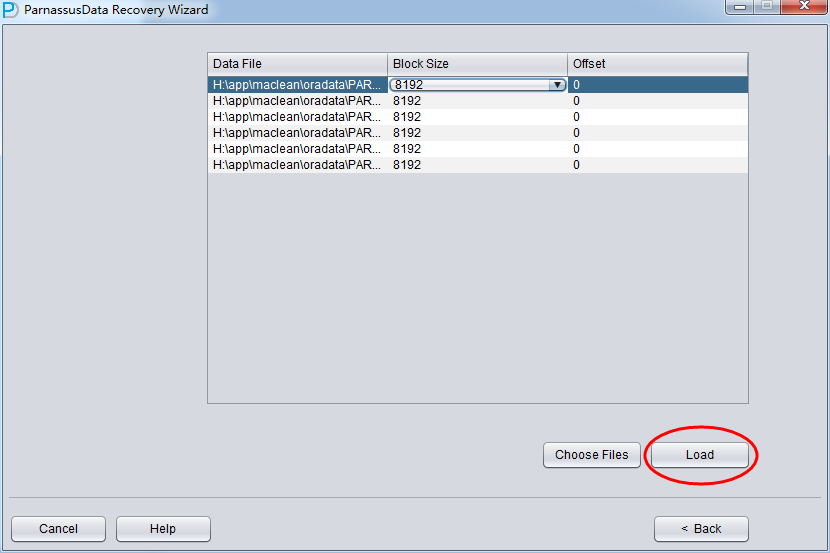
PRM-DUL read Oracle dictionary directly, and recreate a new dictionary in embedded database. It can help us to recuse most types of data in Oracle DB.
After recreating dictionary, the dialog show character information:
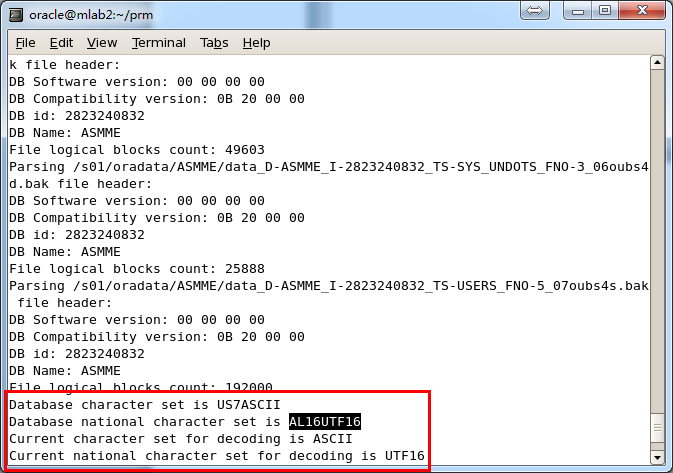
Attention: PRM-DUL supports multiple languages and multiple Oracle character set. However, the prerequisite is the OS had installed specified language packages. For example, on Windows, if you didn’t install Chinese language package, even Oracle database characters are independent and support ZHS16GBK, PRM-DUL would display Chinese as messy code. Once the Chinese language package is installed on OS, PRM-DUL can display multibyte character set properly.
Similarly, on Linux, it need font-Chinese language package.
| [oracle@mlab2 log]$ rpm -qa|grep chinesefonts-chinese-3.02-12.el5 |
After loading, in PRM-DUL GUI, it displayed database tree diagram by database users.
Click Users, you can find more users, for example, if user want to recover a table under PARNASSUSDATA SCHEMA, click PARNASSUSDATA, and double click that table:
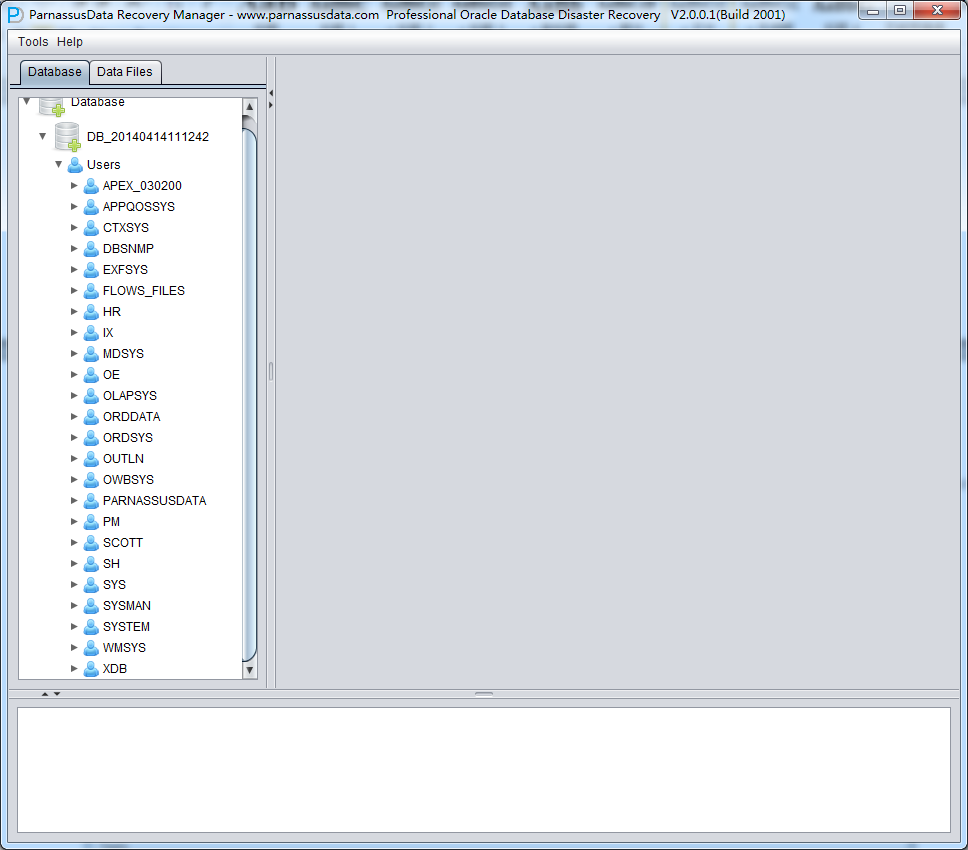
Previously TORDERDETAIL_HIS had been truncated, so it won’t show any data . Please select unload truncated Data:
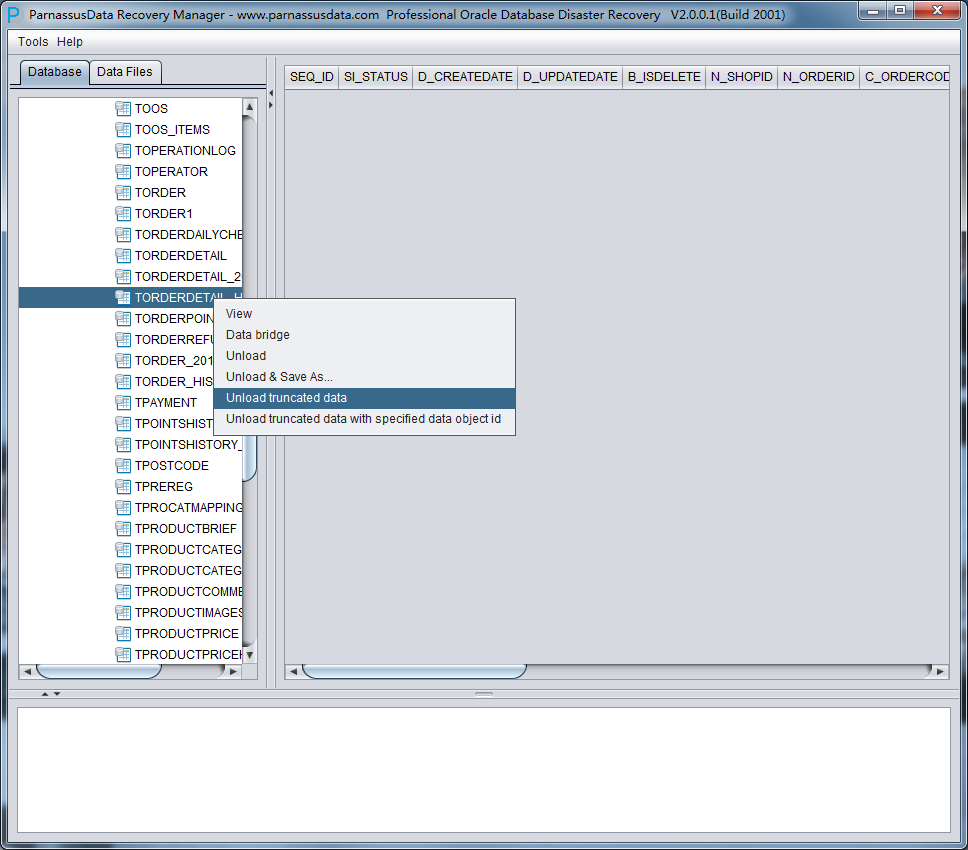
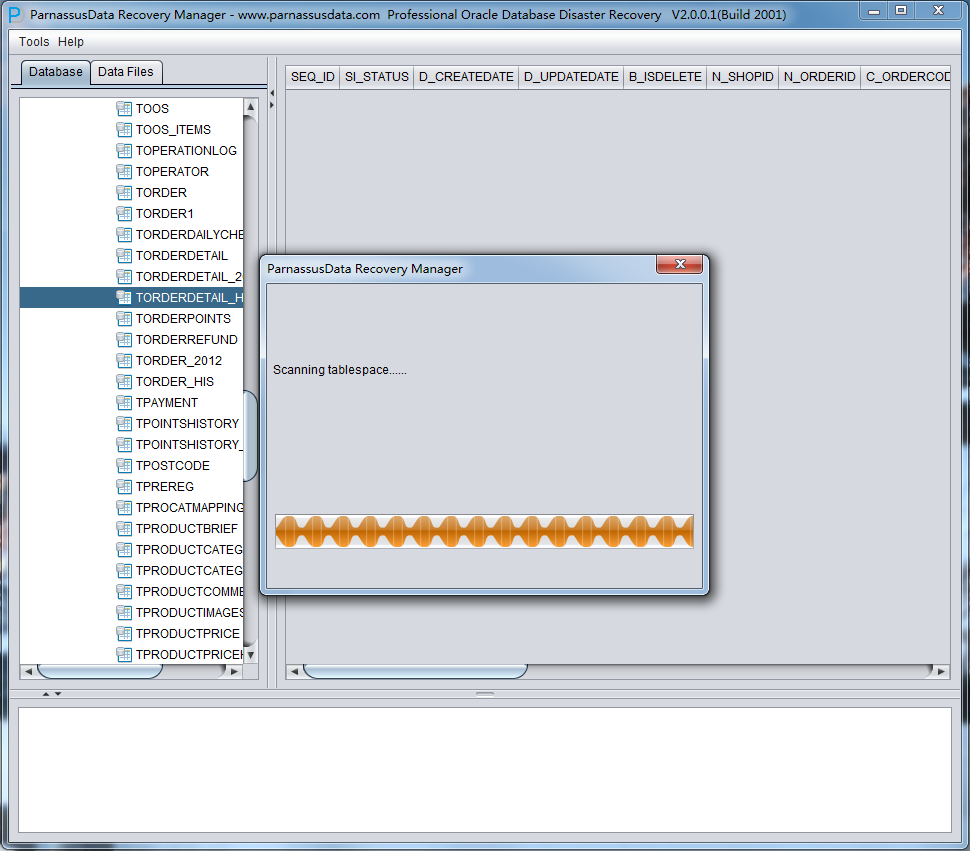
PRM-DUL will scan the tablespace and extract data from truncated table.
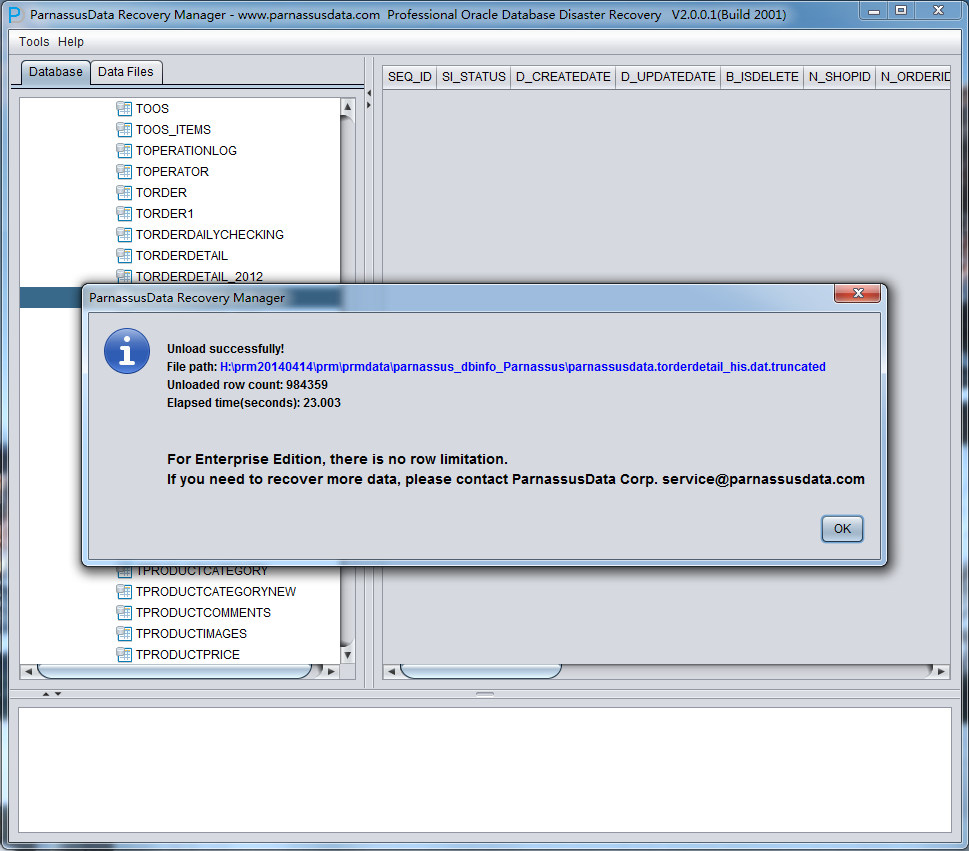
As in the above picture, the truncated TORDERDETAIL_HIS had exported 984359 record, and saved to specified falt file.
In addition, it generated SQLLDR control file for text data importing
|
$ cd /home/oracle/PRM-DUL/PRM-DULdata/parnassus_dbinfo_PARNASSUSDATA/$ ls -l ParnassusData*-rw-r–r– 1 oracle oinstall 495 Jan 18 08:31 ParnassusData.torderdetail_his.ctl-rw-r–r– 1 oracle oinstall 191164826 Jan 18 08:32 ParnassusData.torderdetail_his.dat.truncated
$ cat ParnassusData.torderdetail_his.ctl LOAD DATA INFILE ‘ParnassusData.torderdetail_his.dat.truncated’ APPEND INTO TABLE ParnassusData.torderdetail_his FIELDS TERMINATED BY ‘ ‘ OPTIONALLY ENCLOSED BY ‘”‘ TRAILING NULLCOLS ( “SEQ_ID” , “SI_STATUS” , “D_CREATEDATE” , “D_UPDATEDATE” , “B_ISDELETE” , “N_SHOPID” , “N_ORDERID” , “C_ORDERCODE” , “N_MEMBERID” , “N_SKUID” , “C_PROMOTION” , “N_AMOUNT” , “N_UNITPRICE” , “N_UNITSELLINGPRICE” , “N_QTY” , “N_QTYFREE” , “N_POINTSGET” , “N_OPERATOR” , “C_TIMESTAMP” , “H_SEQID” , “N_RETQTY” , “N_QTYPOS” )
|
When you import data to original table, ParnassusData strongly recommends you to modify SQLLDR table name as a temp table, it would not impact your previous environment.
|
$ sqlldr control=ParnassusData.torderdetail_his.ctl direct=yUsername:/ as sysdba//user SQLLDR to import data//Minus can be used for data comparing
select * from ParnassusData.torderdetail_his minus select * from parnassus.torderdetail_his;
no rows selected
|
After diffing, there is no difference between original data and PRM-DUL exported data.
PRM-DUL successfully recovered the truncated table
CASE 2: Recovery mis-truncated table by DataBridge
In Case 1, we use traditional unload+sqlldr for data recovery, but actually ParnassusData would like to strongly recommend using DataBridge Feature for recovering.
Why use DataBridge?
- Traditional unload+sqlldr means a copy of data needs to be saved as flat file on filesystem first, data has to be loaded into Unicode text file and then inserted into destination database by sqlldr, this will take double storage and double time.
- DataBridge can extract data from source DB and export to destination DB without any intermediary.
- Once the data arrived destination DB, user can begin to validate them.
- If source and destination database located on different servers, then read/write IO will be balanced on two servers , MTTR will be saved.
- If DataBridge is used in truncated table recovery, it is very convenient that truncated data can be exported back to problem database directly.
DataBridge is very simple and convenient. Right click the table on the left side, and select DataBridge:
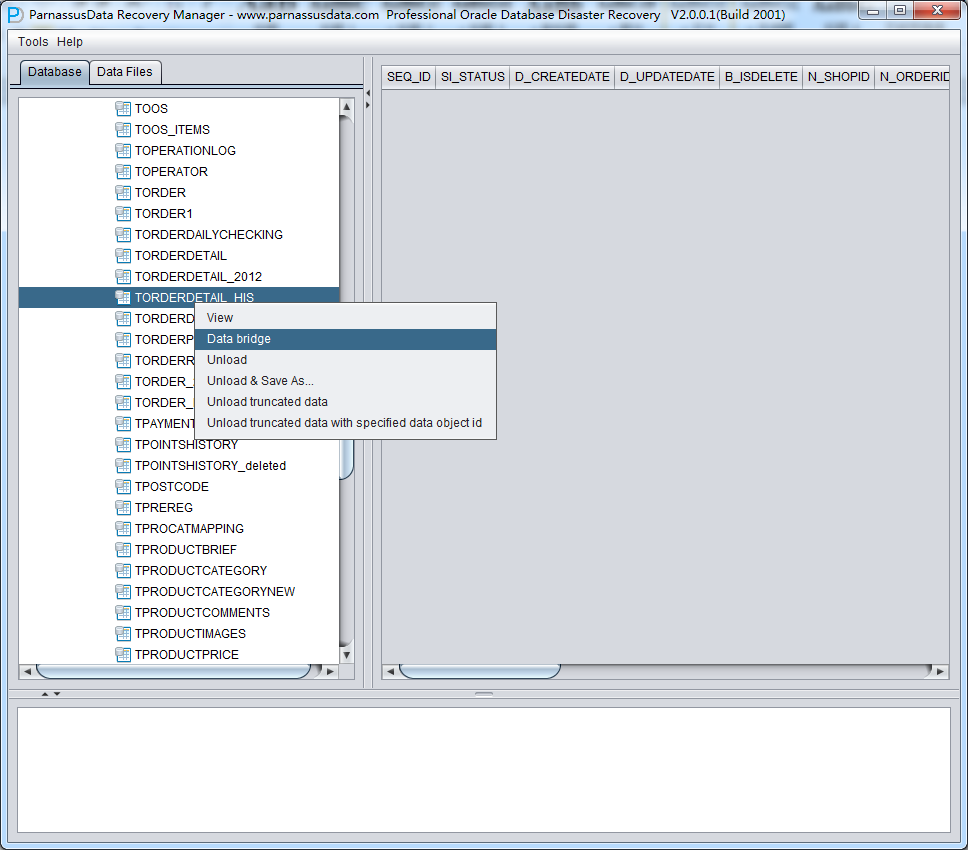
As the first time to use DataBridge, DB connection information is necessary, which is similar with SQL Developer connection, including: DB host, Port, Service_Name and Account information.
Attention: DataBridge will save data to the specified schema given in the DB connection.
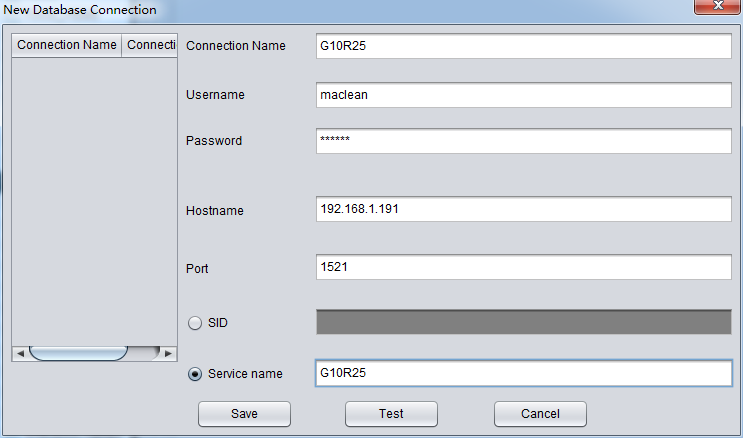
AS above G10R25 connection, user is maclean, and the corresponding Oracle Easy Connection is
192.168.1.191:1521/G10R25。
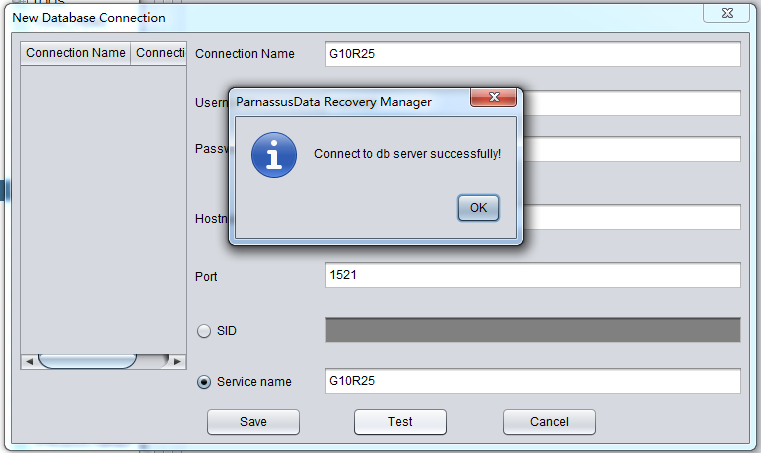
After inputting the account/connection information, you can use test for connection testing. If return message is “ Connect to DB server successfully “, the connection is done and click to save.
After saving connection and go to DataBridge window, please select Connection G10R25 at the drop down list.
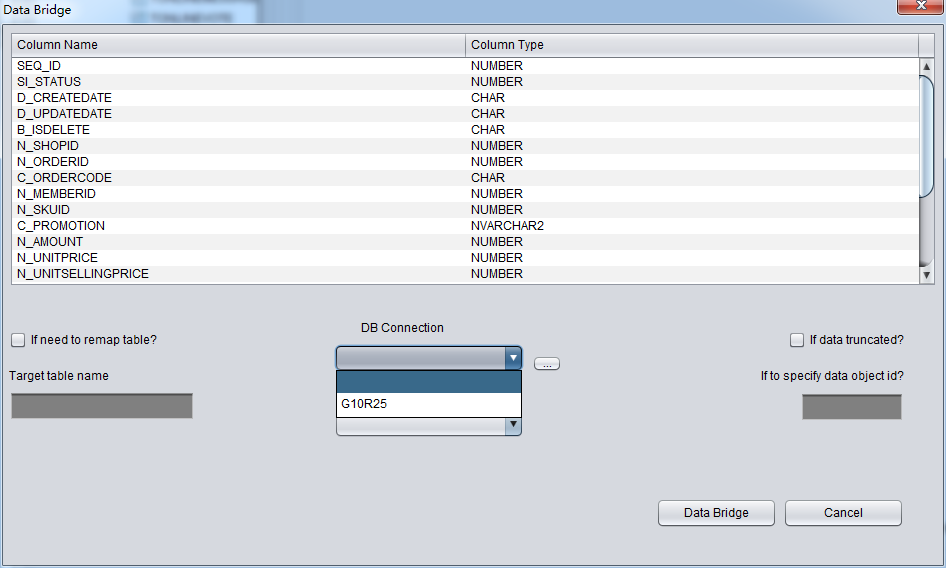
If your DB connection is not in the drop down list, please click DB connection Button, which is highlighted in red.
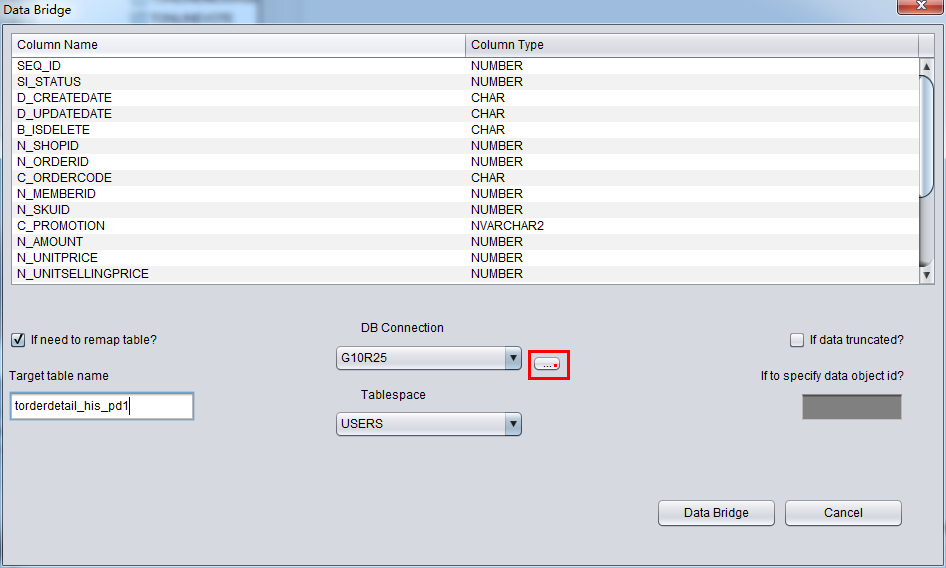
After selecting DB Connection, Tablespace dropdown list will be selectable:
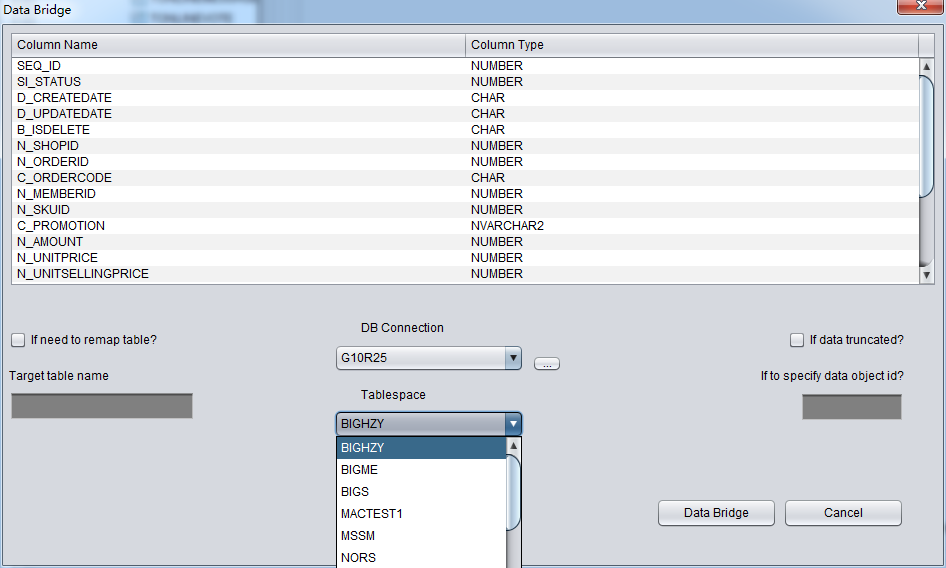
Attention on DataBridge recovering truncated/dropped table: when you recovering truncated/dropped and insert data back to source DB, users should choose another tablespace which diffs from the original tablespace. If export data into same tablespace, oracle will reuse space which stores truncated/dropped table, and can make data overwritten, we will lose the last resort to recover the data.
For example, we truncated a table and would like to user DataBridge to recover data back to source database, but we would like to use another table name. Original table name is torderdetail_his, and user can select “if need to remap table” and input proper destination name, as below:
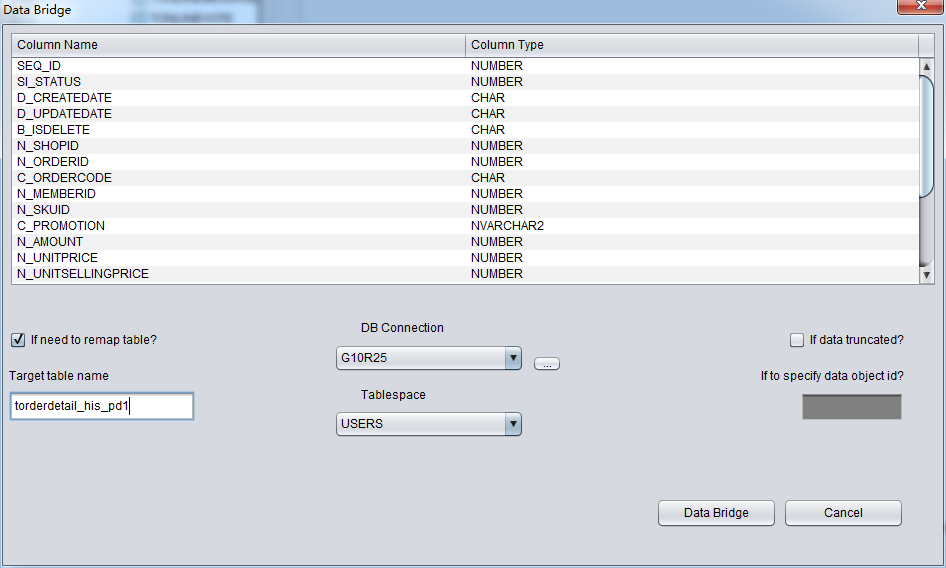
Attention: 1) For destination DB which already had the same table name, PRM-DUL will not recreate a table but append all recovered data. 2) For destination DB which did not have source table name, PRM-DUL would try to create table and recover the data.
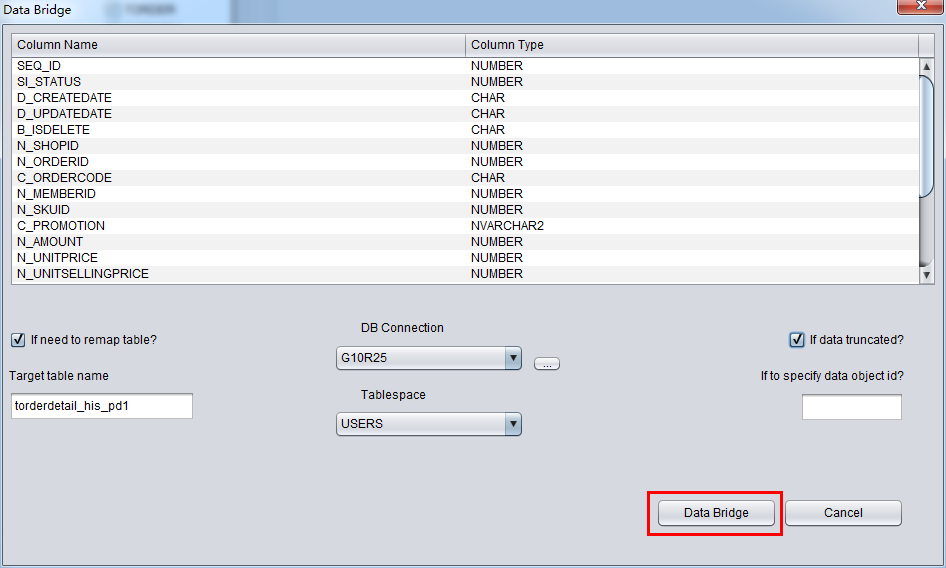
In this case, we would recover Truncated data, therefore, please select “if data truncated?” checkbox, Or, PRM-DUL would do regular data extraction, but not Truncated data.
Truncate recovery methodology is: Oracle will only update table DATA_OBJECT_ID in data dictionary and segment header. Therefore, the real data will not be overwritten. Due to the difference between dictionary and DATA_OBJECT_ID, Oracle server process will not read truncated data while scanning table. But, the real data is still there.
PRM-DUL will try to scan 10M-bytes blocks which are behind of the table’s segment header, if some blocks with smaller DATA_OBJECT_ID than the object’s current DATA_OBJECT_ID, then PRM-DUL thinks it find something useful.
There is a blank input field called ”if to specify data object id”, which let user input Data Object ID. Usually, you don’t need to input any value, unless the recovery does not work. We suggest user to contact ParnassusData for help.
Click DataBridge button ,then it will start extracting if the configuration is done.
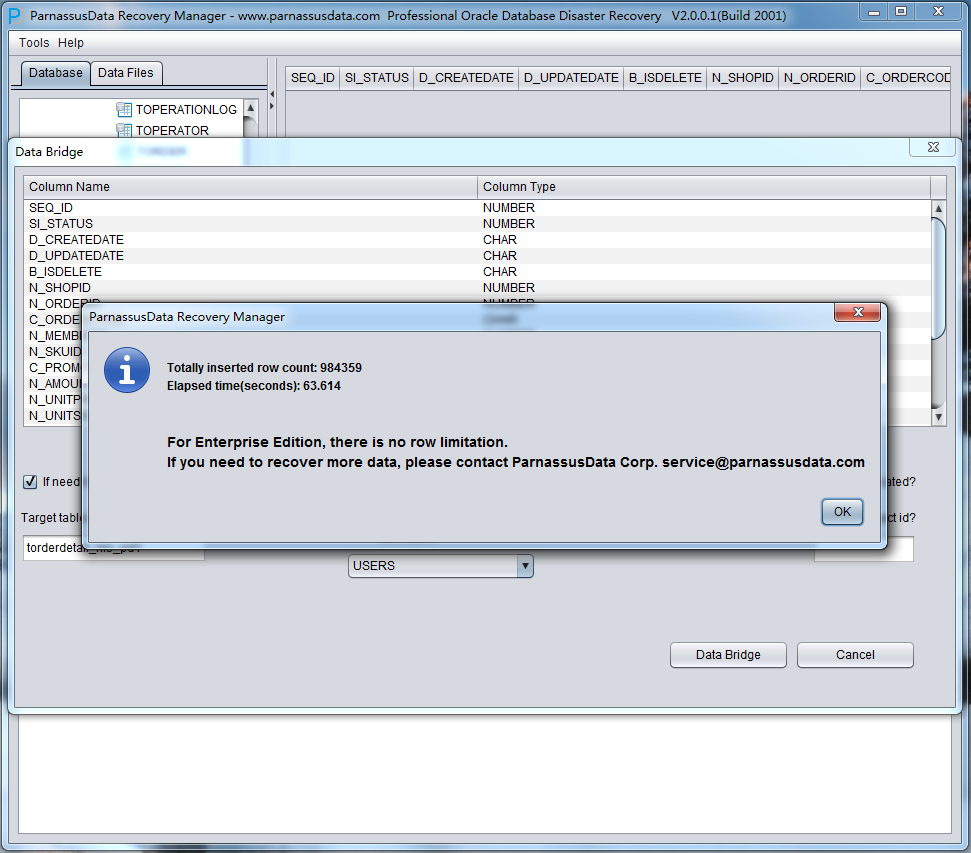
DataBridge will display the successfully rescued rows and elapsed time.
Copyright © 2013, 2019, parnassusdata.com. 版权所有。 dbrecover.com
 沪公网安备 31010802001377号
沪公网安备 31010802001377号