Email: [email protected] 7 x 24 online support!
PRM DUL ORACLE ミスでテーブルをTruncateした時の通常リカバリー
D会社の業務メンテナンス技術者は製品データベースをテスト環境として、あるテーブルの全てのデータをTRUNCATEした。DBAはリカバリーし てみたが、最新なバックアップが使えなくなったことに気づき、バックアップから該当するテーブルの記録をエクスポートできなかった。そのとき、DBAは PRMを採用し、TRUNCATEしたデータをリカバリーすることにした。
その環境で、全てのデータベースファイルは使用可能で健全のため、ユーザーはディクショナリーモードでシステムテーブルスペースのファイルとTRUNCATEDされたテーブルのファイルををロードするだけでOKです。
|
create table ParnassusData.torderdetail_his1 tablespace users as select * from parnassusdata.torderdetail_his;
|
PRMを起動し、Tools => Recovery Wizardを選択する。
Nextをクリックする。
このTRUNCATEシーンではASMストレージを選んでいないため、ディクショナリーモード(Dictionary Mode)だけを選んでいればいい。
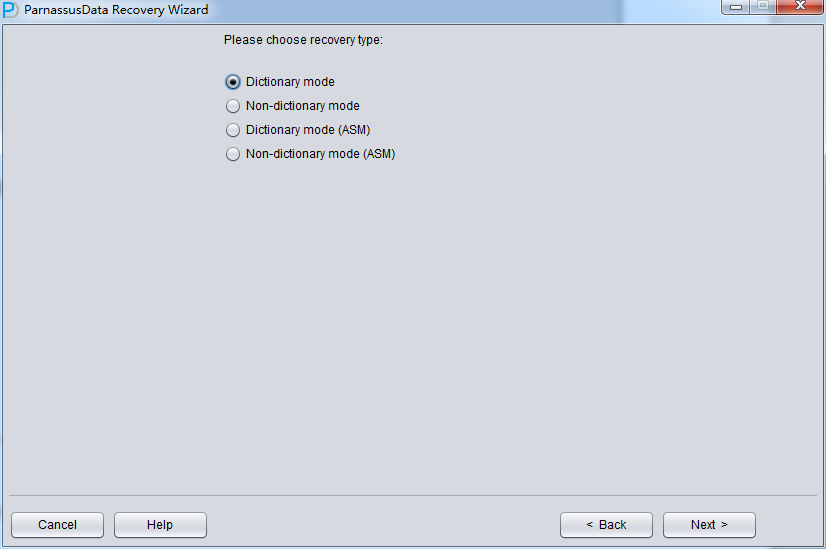
次のステップで、いくつのバラメタを選択する必要がある:EndianエンディアンとDB NAME
Oracleファイルはオペレーションシステム(OS)によって、違ったEndianエンディアン形式を採用し、エンディアンと該当するプラットフォームが以下ご覧のとおり:
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
例えば、伝統的なUnix AIX-Based Systems (64-bit) 、HP-UX (64-bit)ではBig Endianをつかっている、ここではBig Endianに変更する:
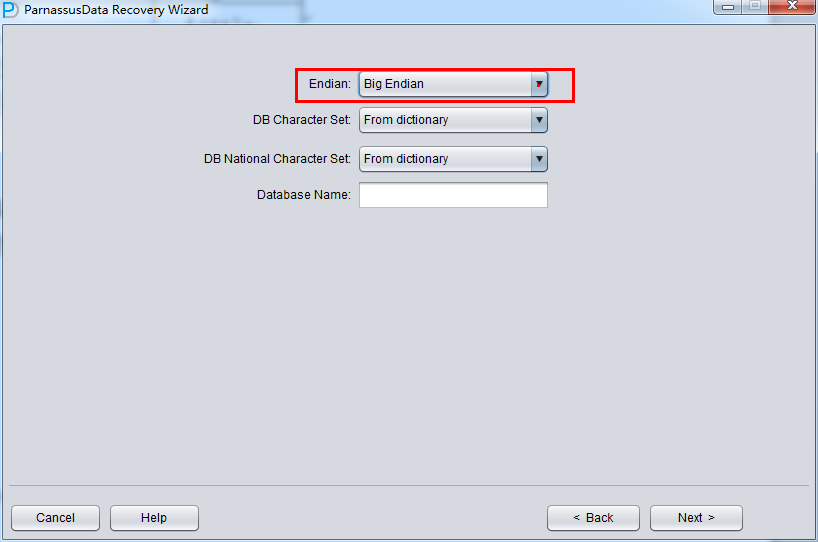
さもないと、Linux x86-64 、WindowsではデフォルトのLittle Endianままになる。
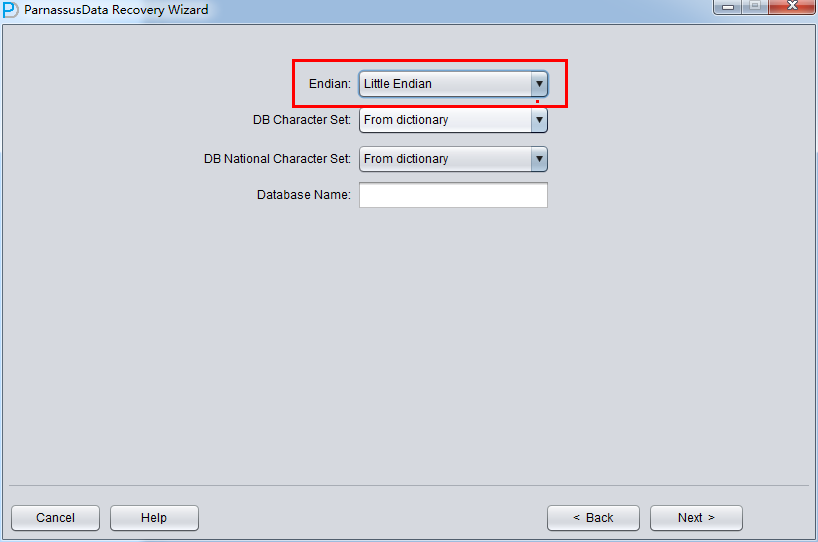
注意事項:もし、ファイルがもともとはAIX(つまりBig Endian)に生成するなら、都合のいいため、これらのファイルをWindowsサーバへコーピーし、PRMによってデータをリカバリーするなら、元のBig Endian形式に選ぶ必要がある。
ここでは、例のファイルがLinux x86にあるため、EndianをLittleに変更し、Database name入力する。(ここに入力したデータベース名は名前だけで、データベースホントのDBNAMEにいみしていない、PRMlのLicense検出メカ ニズムがつかっているのはここに入力したDatabase Nameじゃなく、ホントのDBNAMEをつかっているから):
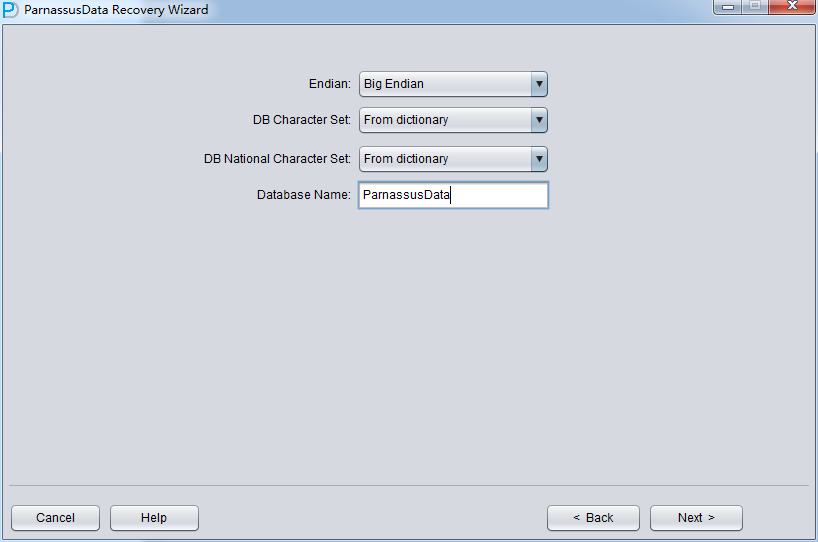
Nextをクリックする。
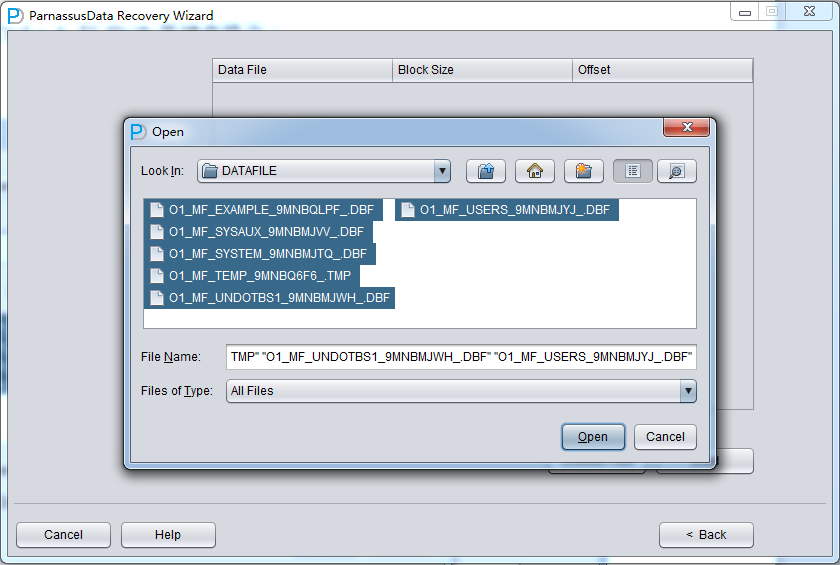
Choose Filesをクリックして、一般的には、データベースが大きくなければ、データベースにある全てのファイルを選定する必要がある。データベースが大きで、 そしてデータテーブルがどこのフィイルにあるかをしっていれば、SYSTEMテーブルスペースのフィイルとデータテーブル(必要)を含むフィイルしかえら べない。
注意:ChooseインターフェースではCtrl + A とShiftなどキーボード操作を支持している。
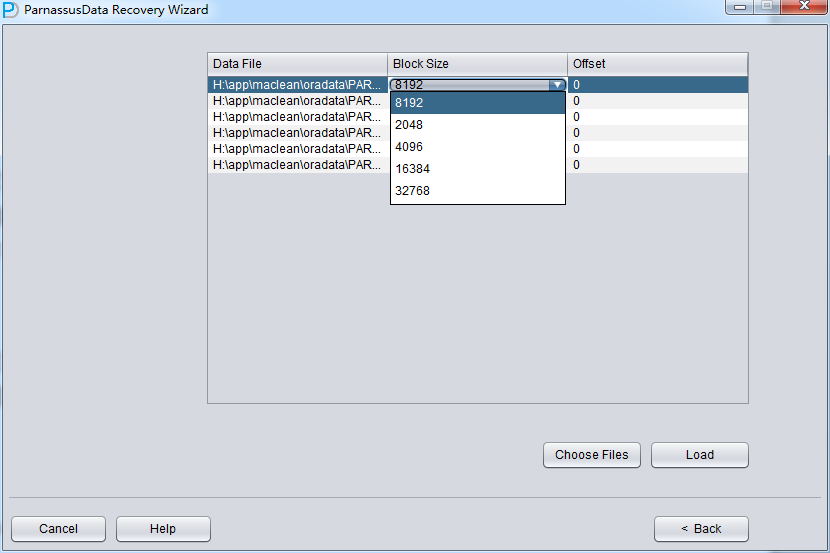
後で、特定のファイルのBlock Sizeを指定する。つまり、Oracleデータブロックの大きさをしていする必要がある。ここは実際に応じて変更すればいい。例えば、 DB_BLOCK_SIZEは8Kだが、一部のデータブロックテーブルスペース指定が16Kから、テーブルスペースが8Kじゃないデータブロックの BLOCK_SIZEを変更すればいい。
ここのOFFSETバラメタは主にRAWデバイスにファイルを格納するときにたいおうするためのバラメタです。
もし、RAWデバイスフィイルをつかっているときにOFFSETをわからなければ、$ORACLE_HOME/binのdbfsizeツールを使って確認すればいい。したのきいろの部分が示したように、ここのRAWデバイスは4KのOFFSETをもっている。
|
$dbfsize /dev/lv_control_01
Database file: /dev/lv_control_01 Database file type: raw device without 4K starting offset Database file size: 334 16384 byte blocks |
このシーンで全てのファイルは8KのBLOCK SIZE、そしてファイルシステムはOFFSETがないので、Loadをクリックする。
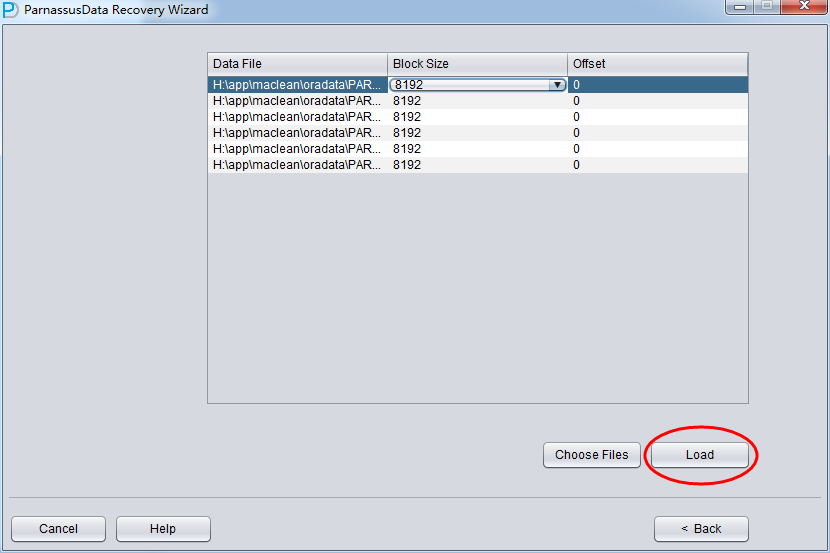
Loadステップに、PRMはSYSTEMテーブルスペースでOracleデータディクショナリー情報を読み取り、自らのDerbyでデータディクショナリー新規することによって、PRMがOracleデータベースにあるさまざまなデータを操作できる。
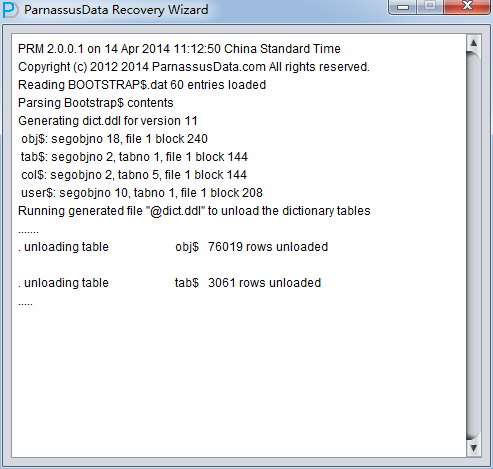
Load完成したあと、バックグラウンドでデータベース・キャラクタ・セットと各国語キャラクタ・セットをエクスポートする。
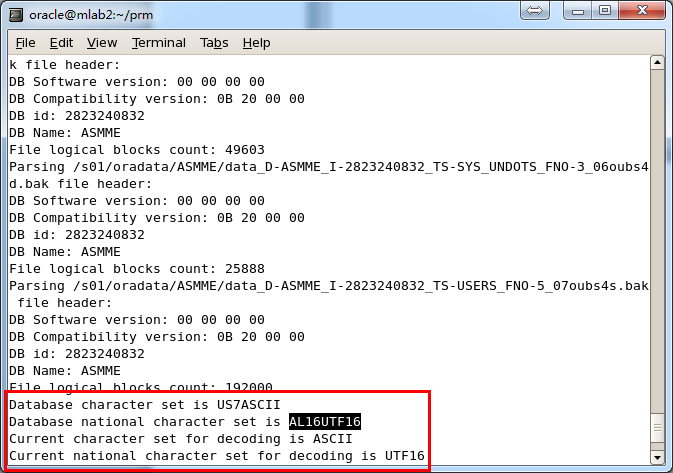
PRMは多国言語およびOracleデータベースマルチキャラクタセットを支持しているが、PRMでデータをリカバリーしたいオペレーションシステ ムを事前に該当するLanguage Packsをインストールしないといけない。たとえば、Windowsオペレーションシステムでは中国語Language Packsをインストールしていないが、ORACLEデータベース・キャラクタ・セットがオペレーションシステムから独立しているから、このシーンでつ かっているORACLEデータベース・キャラクタ・セットがZHS16GBKキャラクタ・セットで、オペレーションシステムは中国語を支持していないです が、このシーンでサーバに配置していないOracleクライアントは影響をうけず、正確にデータをしめすことができる。
でも、PRMをつかうにはPRMでデータをリカバリーしたいオペレーションシステムが事前に該当するLanguage Packsをインストールする必要がある。例えば、ユーザーがZHS16GBKの中国語キャラクタ・セットデータベースをリカバリーしたいとき、オペレー ションシステムが中国語Language Packsをインストールした必要がある。
Linuxにもfonts-chinese中国語フォントパッケージをインストールする必要がある。
Load完成したあと、PRMインターフェースの左側にはデータベースユーザーPacketによる樹形図が現れる。
USERSをクリックし、いろんなユーザー名がでる。例えば、ユーザーがPARNASSUSDATA SCHEMAの下のテーブルをリカバリーしたいが、PARNASSUSDATAをクリックして、テーブルをダブルクリックする。
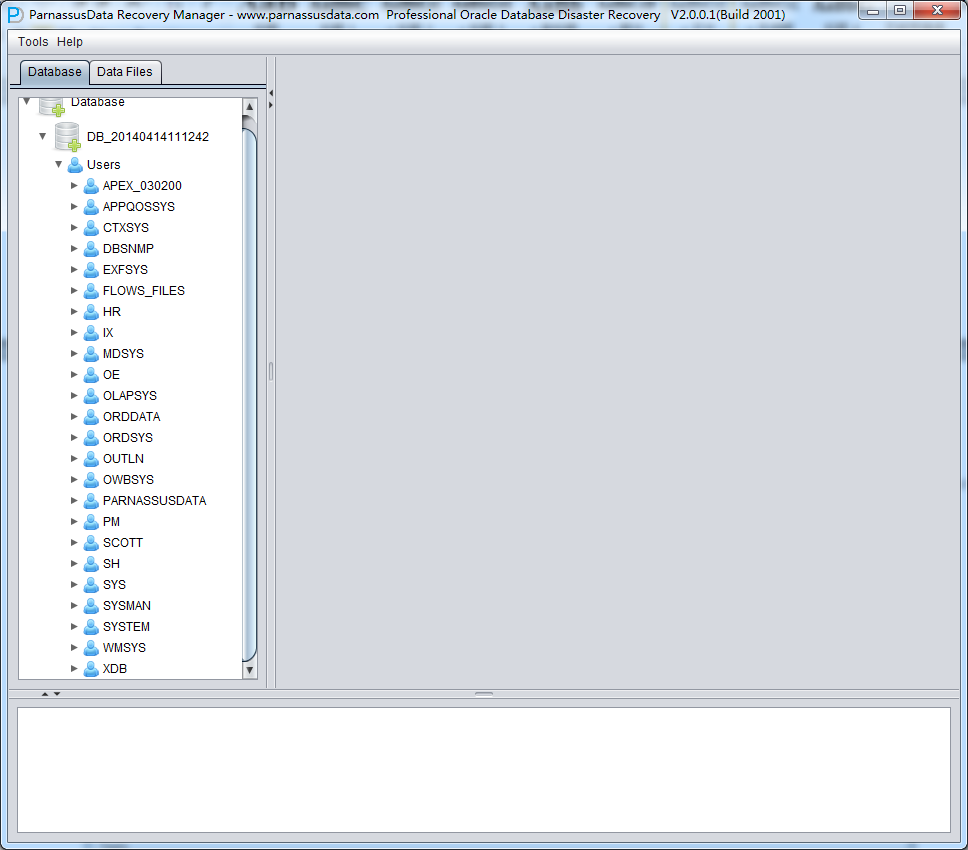
該当するTORDERDETAIL_HIS表がその前にTRUNCATEDされたから、ダブルクリックしてもデータを示せない。そのとき、テーブルにマウスの右ボタンでUnload truncated dataをクリックする。
PRMはそのテーブルを含むテーブルスペースをスキャンして、truncatedされたデータを抽出できる。
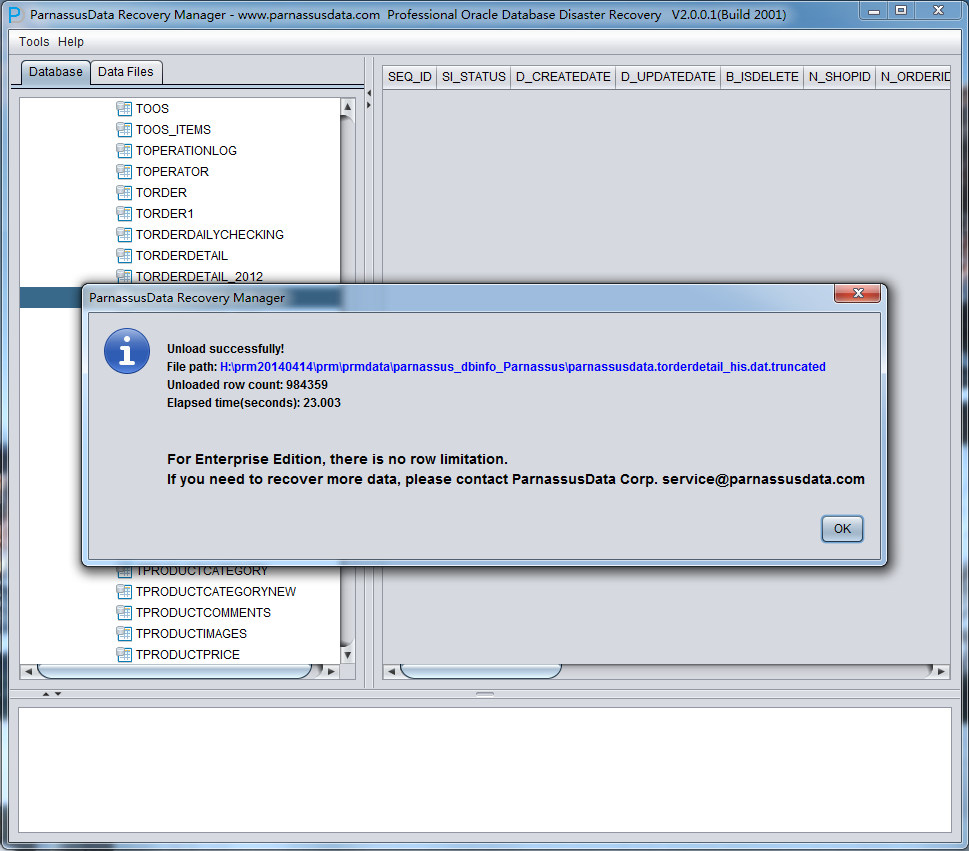
上のグラフのように、TRUNCATEされたTORDERDETAIL_HISテーブルからすべての984359の記録、指定されたパスに格納する。
|
$ cd /home/oracle/prm/prmdata/parnassus_dbinfo_PARNASSUSDATA/
$ ls -l ParnassusData* -rw-r–r– 1 oracle oinstall 495 Jan 18 08:31 ParnassusData.torderdetail_his.ctl -rw-r–r– 1 oracle oinstall 191164826 Jan 18 08:32 ParnassusData.torderdetail_his.dat.truncated
$ cat ParnassusData.torderdetail_his.ctl LOAD DATA INFILE ‘ParnassusData.torderdetail_his.dat.truncated’ APPEND INTO TABLE ParnassusData.torderdetail_his FIELDS TERMINATED BY ‘ ‘ OPTIONALLY ENCLOSED BY ‘”‘ TRAILING NULLCOLS ( “SEQ_ID” , “SI_STATUS” , “D_CREATEDATE” , “D_UPDATEDATE” , “B_ISDELETE” , “N_SHOPID” , “N_ORDERID” , “C_ORDERCODE” , “N_MEMBERID” , “N_SKUID” , “C_PROMOTION” , “N_AMOUNT” , “N_UNITPRICE” , “N_UNITSELLINGPRICE” , “N_QTY” , “N_QTYFREE” , “N_POINTSGET” , “N_OPERATOR” , “C_TIMESTAMP” , “H_SEQID” , “N_RETQTY” , “N_QTYPOS” )
|
データをソーステーブルにロードする(注意:元の環境を上書きされないように、SQLLDRコントロールフィルタを変更するときに、一時的なテーブルをロードしてください。
|
$ sqlldr control=ParnassusData.torderdetail_his.ctl direct=y
Username:/ as sysdba 以上はsqlldrでリカバリできたデータの実例です。
Minusによって、リカバリしたデータを比べることもできる select * from ParnassusData.torderdetail_his minus select * from parnassus.torderdetail_his;
no rows selected
|
テスト中、TRUNCATEと元のテーブルと比べて、記録が完全に同様に見える。
それは、PRMはTRUNCATEテーブルの記録をリカバリできたから。
リカバリシーン2 過ちでTruncateされたテーブをバイパスリカバリ
シーン1では、通常のunload+sqlldr方法を採用したが、実際使用中、私たちはかなり工夫して設計できたDataBridgeデータバイパスモードを勧めます。
なぜデータバイパスモードを使う必要があるでしょう?
通常のunload+sqlldr方法はソースデータ、抽出するデータ、および目標のデータを格納するスペースが必要、つまり、もとの空間の二倍を要求する。バックアップのスペースさえ用意できない企業に対して、これはかなり厳しい要求だと思います。
データバイパスとunload+sqlldrモードの一番大きな違いはデータバイパスはソースリポジトリからデータを抽出し、目標データベースへ転移して、もとのフィルタシステムに抽出データを格納する必要はない。
データバイパスによって、目標データベースに転移されたデータは元々構造化されたから、SQLで一貫性と整合性をかくにんできる。
データバイパスの目標データベースは異なるマシンにある場合は、ソースデータベースに対して、読み取りしかできない、読み書きIOは二つのマシンに配置し、PRMリカバリスビートがよく速くなる。
ユーザーリカバリしたいのはTruncateデータの場合に、バイパスによってすぐにソースデータベースに戻れる、リカバリ作業はマウスをクリックするだけですませる。
データバイパスモードを使うには、通常モードと同じ、左側の樹形図に必要なテーブルを選んで、右ボタンでDataBridgeオプションをクリックする。
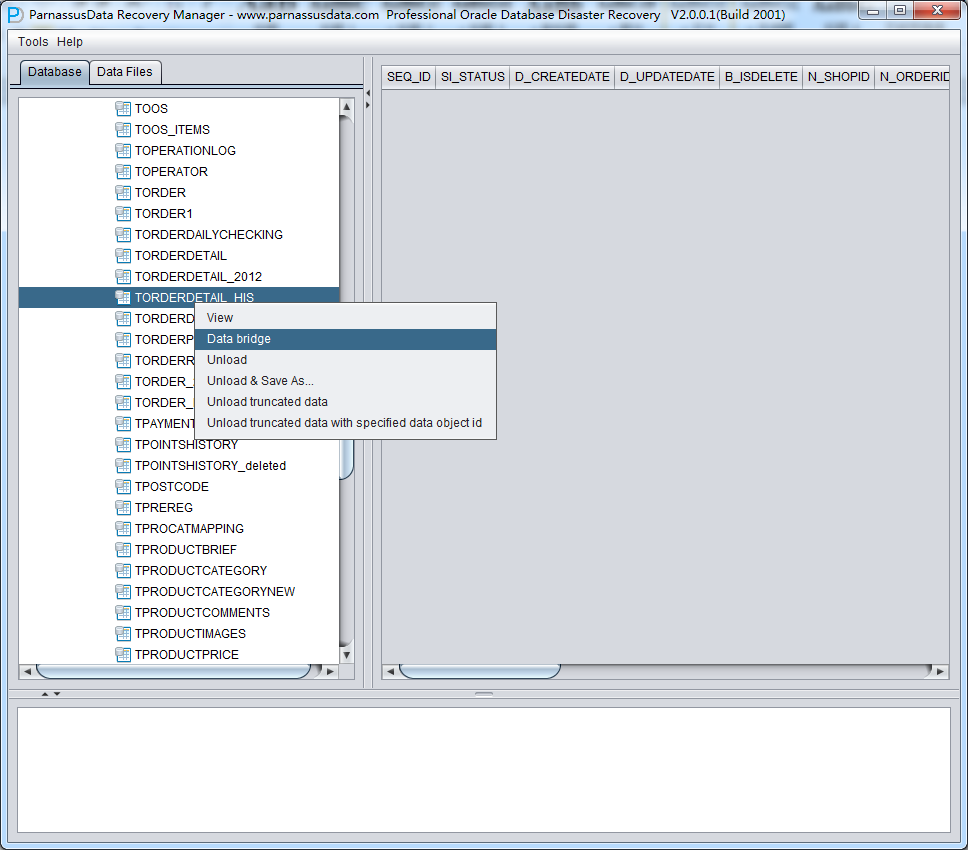
初めてデータバイパスモードを使うときに、まずは目標データベースとつながる情報を入力する必要がある。これはSQLDEVELOPERに Connectionを構造する作業に似ている。これは目標データベースのホスト、ポート、Service_Nameおよびユーザー登録情報も含んでい る。ここに入力したユーザー情報は、後でデータバイパスを使う目標データベースのユーザーのことだから、つまり、ソースリポジトリから抽出したテーブルは 指定された目標データベースユーザーへ転移する。
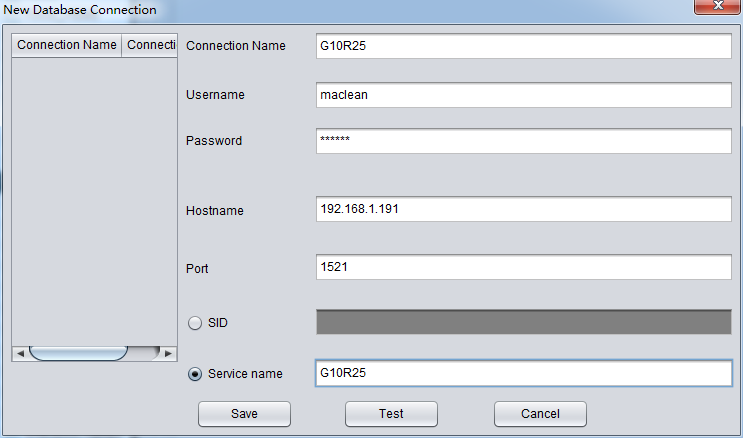
このように、G10R25というリンクを構造した、ユーザーはmaclean、該当するoracle Easy Connection接続文字列は192.168.1.191:1521/G10R25。
以上のようなデータベース情報入力を完成したら、Testボタンをクリックして、リンクオプションが使えるか否かを確認できる。もし、“ Connect to db server successfully “が戻ってきたら、いまリンクが使えるということを意味する。そのままSaveをクリックして、セブすればいい。
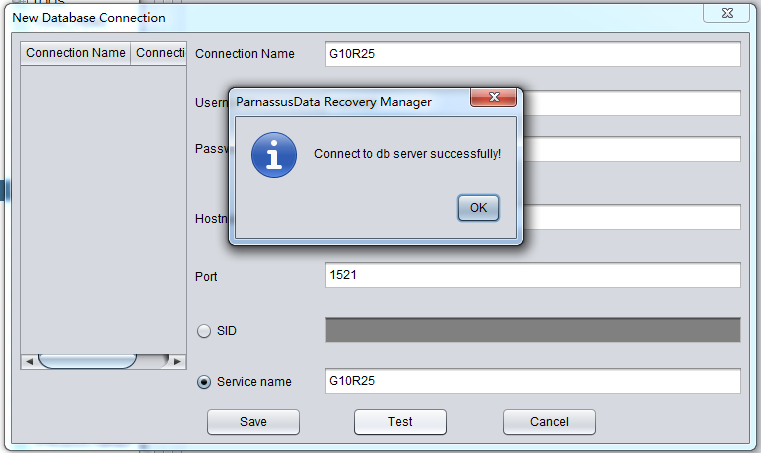
セブできたら、DataBridgeインタフェースに入って、まずはDB Connectionドロップダウンリストに、先に追加したConnection G10R25を選択する:
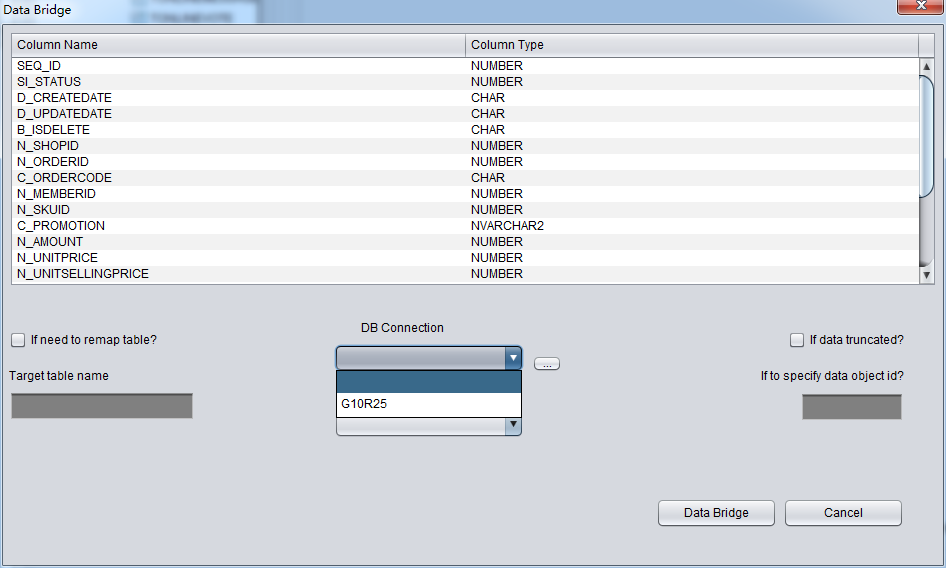
DB Connectionドロップダウンリストに必要とするデータベースリンクが現れていないなら、DB connectionのそばにある「…」ブタンを押してDB Connection:を追加してください
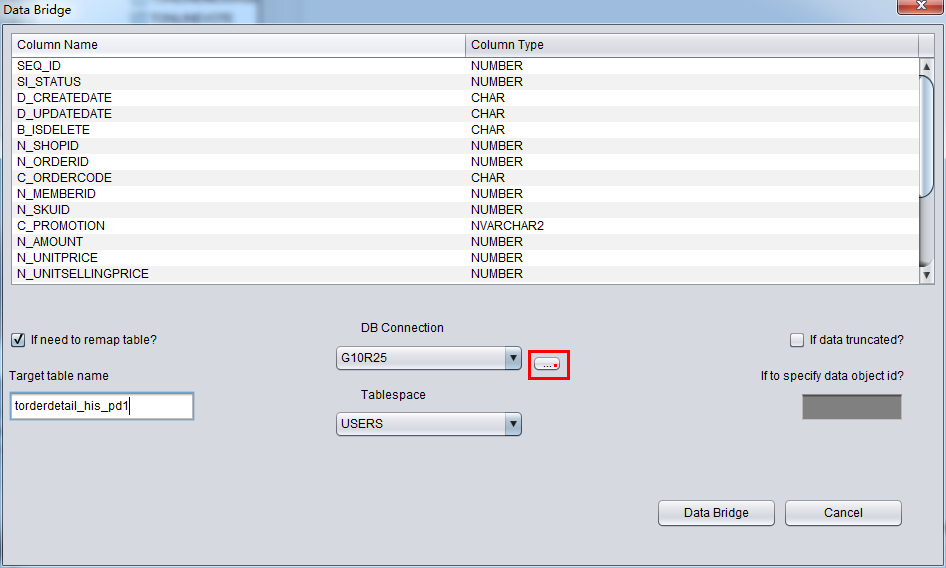
DB Connectionを正確に選んでいたら、Tablespaceドロップダウンリストが使えるようになる、ふさわしいテーブルスペースを選んでください。
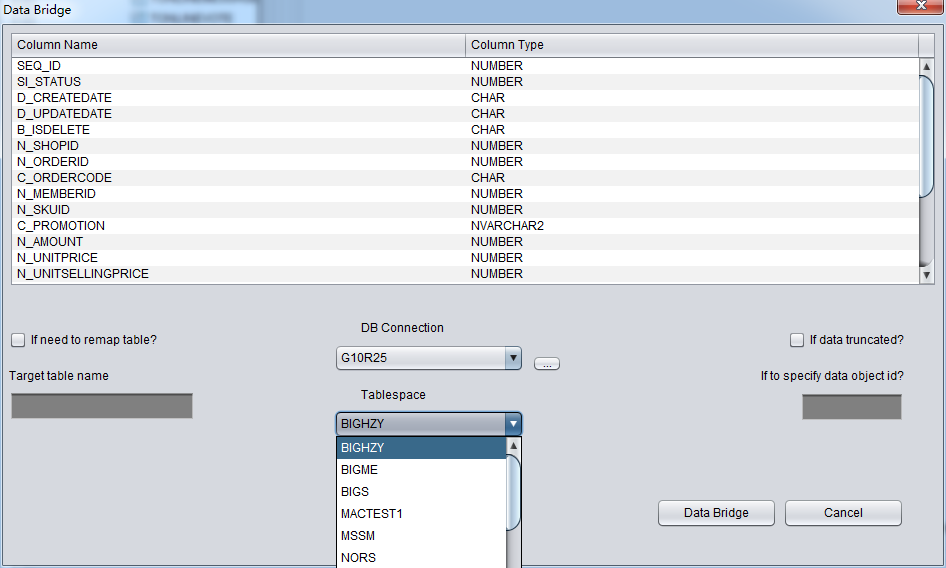
Data Bridgeを使って、truncateをリカバリするときに、以下のようなことを注意してください:ソースリポジトリからtruncateデータをリカ バリするときに、databridgeオプションを使って、データをソースデータベースへ伝送する場合(ソースリポジトリじゃなければ問題ない)、 Databridgeを新規テーブルにインサートするアドレスはソースデータベースにtruncateされたアドレスにしないでください。さもなければ、 truncateされたデータをリカバリしながら、リカバリされたばかりのデータが上書きされることになる。こういう時に上書きされたデータがリカバリで きないので、ご注意をください。databridge+を使ってデータをソースデータベースにリカバリするとき、およびdatabridgeにテーブルス ペースを指定する場合、ぜひ、リカバリしたいテーブルスペースをつかわないでください。
ユーザーはソースリポジトリから目標リポジトリへ伝送するテーブルの名前のマッピングを変更するか否かを選択できる。例えば、ソースリポジトリであ るテーブルがTruncateされた、いまはDataBridgeにより、データをソースリポジトリへリカバリするが、元の名前をつかいたくないで、ほか の名前で格納したいとき、“if need to remap table”を選んでふさわしい名前を入力すればいい:
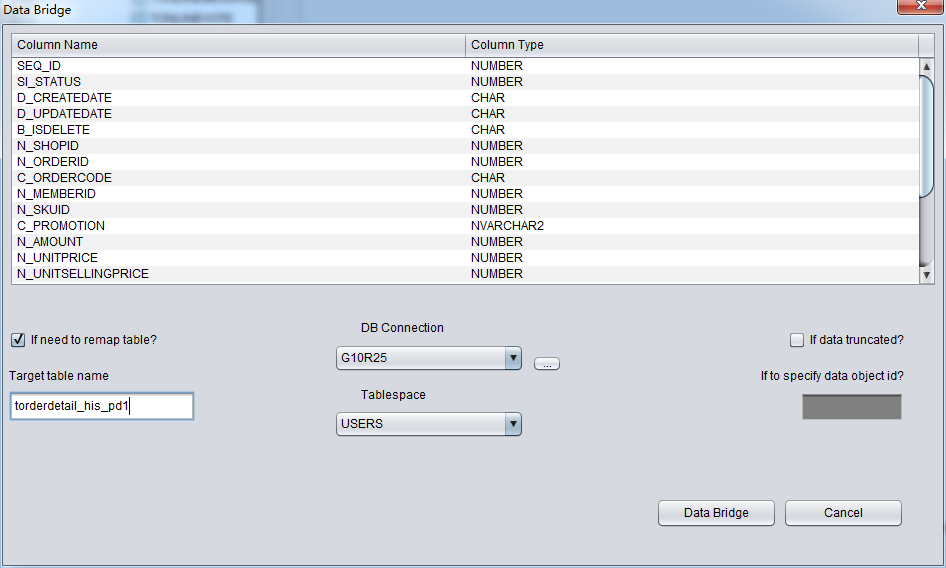
1.目標リポジトリに該当するテーブルの名前がすでに存在している場合に、PRMはテーブルを再構造することじゃなく、既存するテーブルを元にリカバリしたいデータをインサートする。テーブルはもう構造したから、指定したテーブルスペースが無力化になる。
2.目標リポジトリに該当するテーブルの名前がまだ存在していない場合は、PRMが指定したテーブルスペースにテーブルを構造し、リカバリしたいデータをインサートしてみます。
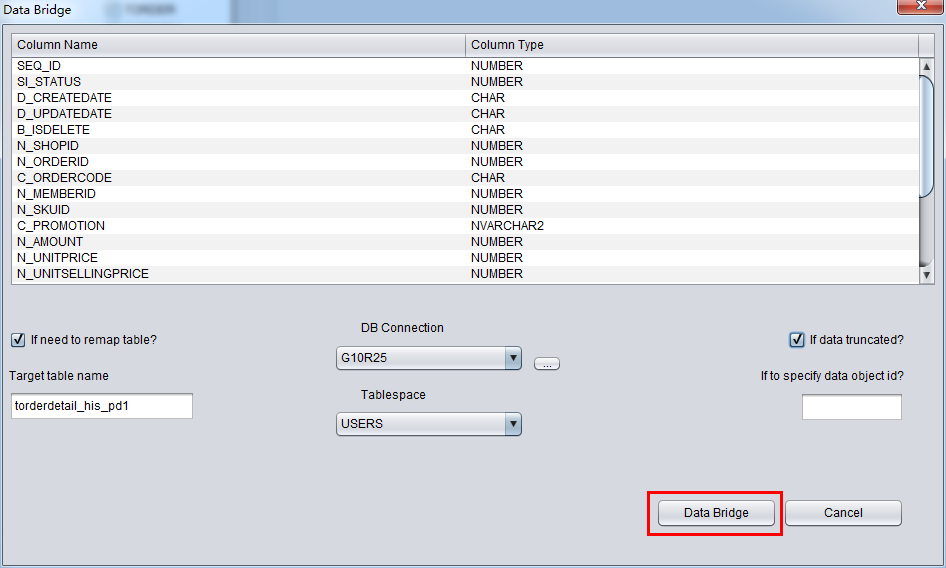
このシーンで私たちがリカバリしたのはTruncateされたデータで、“if data truncated”を選択する必要がある。さもなければ、PRMは通常のモードでデータを抽出するから、Truncateされたデータが見えなくなる。
Truncateデータの原理は、OracleがデータディクショナリーとSegment HeaderにテーブルのData Object IDを更新するが、実際データに一部のブロックが更新されない。データディクショナリーとセグメントヘッダーのDATA_OBJECT_IDがあとのデー タブロックにあるが一致していないため、Oracleサビースプロセスがテーブル全体のデータを読み取るときに、TRUNCATEされたが、まだ上書きさ れていないデータは読み取れない。
PRMは自動スキャンによって、データセグメントヘッダー(Segment Header)がTRUNCATEされた後のデータブロックはTRUNCATEされた前のDATA_OBJECT_IDを判断し、ディクショナリーにテー ブルフィールドの定義と自動獲得したDATA_OBJECT_IDによって、データを抽出する。
そして、”if to specify data object id”というインプットボックスが存在している。これによって、ユーザーがリカバリしたいデータのData Object IDを指定できる。Truncateデータをうまくリカバリできなかったときに限って、ParnassusDataの技術サポートを元に、指定してくださ い。それ以外、何の数値を指定する必要がない。
以上のように、DataBridge配置を正確に配置できたら、データバイパスを実行できる。DataBridgeボタンをクリックしてください:
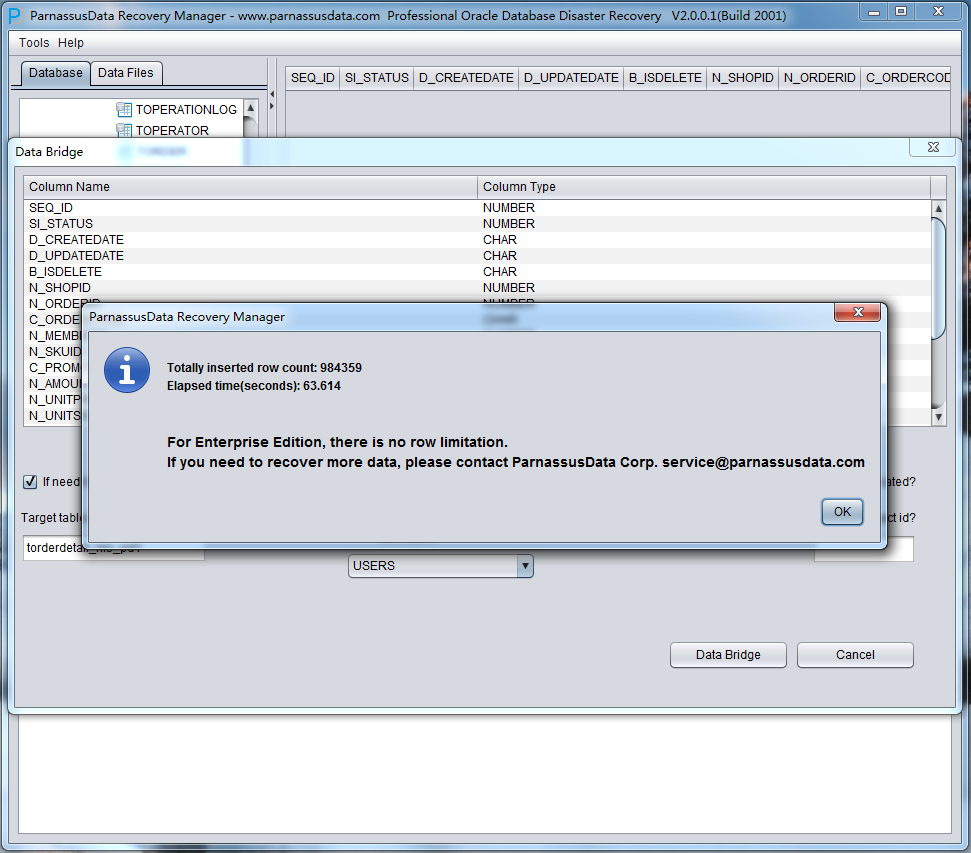
データバイパスが完成したら、伝送できたデータ行数と経過時間を示される。
Copyright © 2013, 2023, parnassusdata.com. 版权所有。dbrecover.com
 沪公网安备 31010802001377号
沪公网安备 31010802001377号